基于PPO-RW的Qwen3-1.7B模型微调与效果分析
本项目基于LlamaFactory平台,通过PPO(近端策略优化)方法微调Qwen3-1.7B模型。训练使用dpo_zh_demo数据集,该数据集包含人类偏好选择,能直接指导模型学习生成更富有情绪、更接近人类语言习惯的回复,而非机械性的内容。
利用人类偏好数据训练奖励模型(Reward Model, RM),由RM对模型生成的候选回复打分,作为PPO的优化信号,促使模型输出更符合人类价值与对话习惯的答案,而不只是“像训练集那样说话”,该类训练具备以下特点。
- 它通过“奖励模型 + PPO”两阶段结构,把人类偏好转成可微分、可度量的标量奖励:RM 负责判断哪类回复更好,PPO 负责让策略在不剧烈偏离原模型能力的前提下持续提高奖励期望,从而实现比纯监督学习更强的偏好对齐能力。
- 其次,PPO-RW 在优化上引入裁剪目标与优势函数(Advantage),限制单步更新幅度,降低在线采样带来的高方差与训练震荡;同时结合 KL 散度惩罚,使微调后的 Qwen-1.7B 既学会“更讨人喜欢的说法”,又最大限度保留原有语言理解与通用生成能力,减少“对齐后能力下降”的风险。
- 最终,PPO-RW 具备更强的探索与自我纠偏能力:模型会在真实生成分布上不断试错、被 RM 反馈、再改进策略;在情绪表达、礼貌程度、指令遵循等主观维度上往往能获得更细腻的提升,成为当前微调大型语言模型的优选方案。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Qwen3-1.7B | 是 | 经过指令微调,参数量约17亿 (1.7B),专为轻量级多语言理解、指令执行与高效对话生成任务打造,在保持模型紧凑的同时依然具备良好的推理能力与语言泛化性能。 |
| 数据集 | dpo_zh_demo | 是 | 风格混杂、内容无关联的片段集合,涵盖金融、宗教、AI和食品等多个领域。 |
| GPU | H800*1(推荐) | - | |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
操作详情
-
使用已注册的LlamaFactory Online账号登录平台,选择[微调/模型微调]菜单项,进入模型微调配置页面,模型选择
Qwen3-1.7B、数据集选择dpo_zh_demo,训练方式选择Reward Modeling,其余参数配置如下图所示。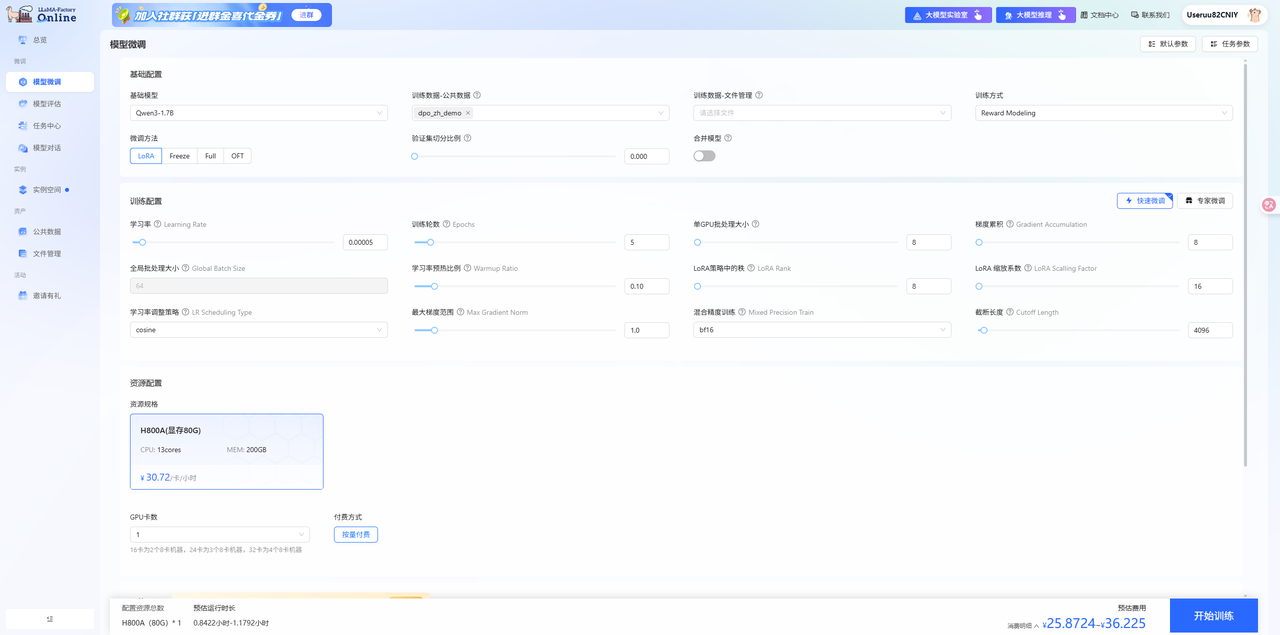
-
单击上图“开始训练”按钮,找到Reward model任务,复制Reward model的路径,如下图所示。
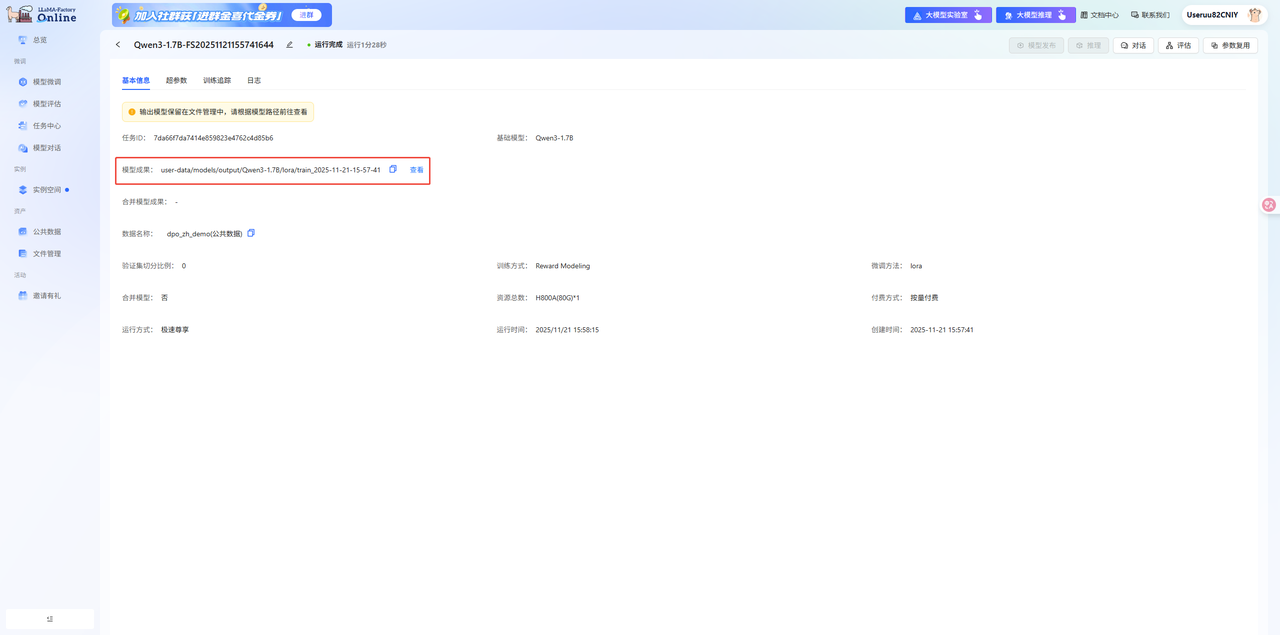
-
切换至[微调/模型微调]页签,进入模型微调配置页面,模型选择
Qwen3-1.7B、数据集选择identity,训练方式选择PPO,并将刚才复制的路径粘贴至奖励模型路径,其余参数配置如下图所示,参数配置完成后,单击下图“开始训练”按钮。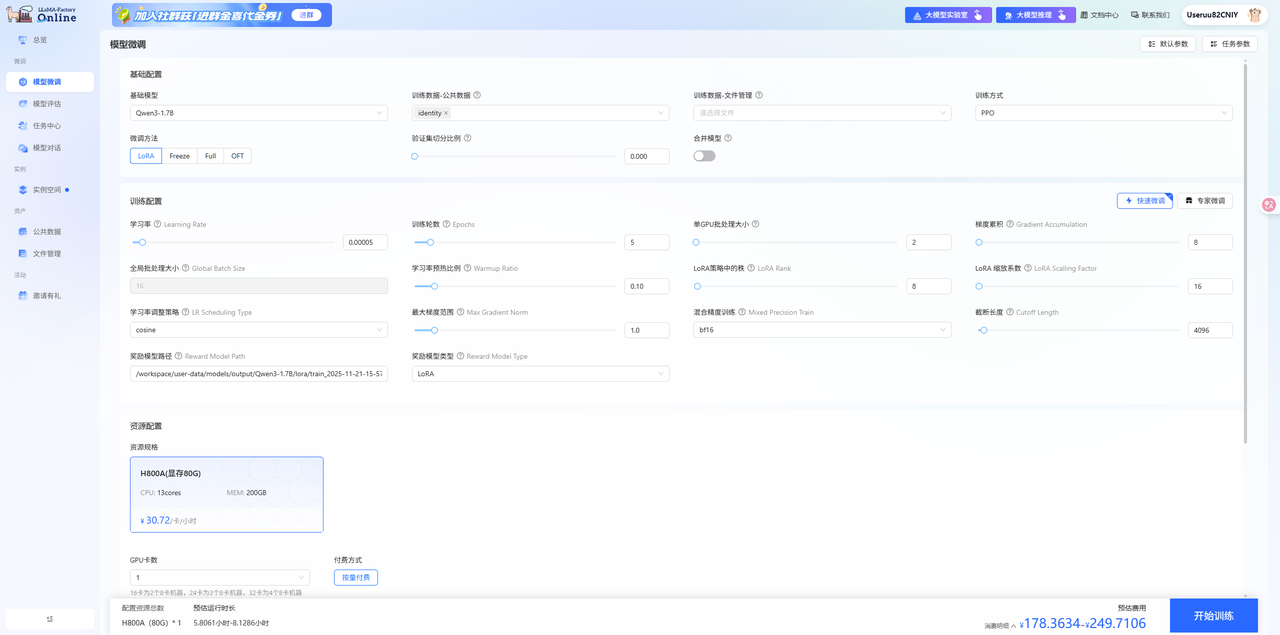
模型对话
-
选择[微调/模型对话]菜单项,加载微调成功的LoRA模型进行对话,如下图所示。
-
为分析模型微调前后的性能差异,我们设计了以下提问进行对话对比:“我有一组不同时间的鼠标坐标/移动数组。我想知道用户悬停在屏幕上的有趣部分;即聚类。我该如何计算这些聚类?”。
微调后模型
-
在[微调/任务中心]找到已完的模型微调任务,单击任务页签的“对话”按钮,进入模型对话页面,输入上述提示词,观察模型回答,模型回答详情可参看“对话详情”。

对话详情
为了从不同时间的鼠标坐标数组中识别用户悬停的有趣区域,可以采用以下步骤结合空间聚类和时间分析:
1. 数据预处理
将时间序列转换为二维坐标点,每个点包含 (x, y, time),以便后续分析。
import numpy as np
data = [(x, y, t) for x, y, t in mouse_data] # 假设mouse_data是原始坐标数组
X = np.array([x for x, y, t in data])
Y = np.array([y for x, y, t in data])
T = np.array([t for x, y, t in data])
2. 空间聚类
使用 KMeans 或 DBSCAN 对坐标点进行空间聚类,识别潜在的区域。
KMeans
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=k).fit(np.column_stack((X, Y)))
labels = kmeans.labels_
DBSCAN
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=2).fit(np.column_stack((X, Y)))
labels = dbscan.labels_
3. 时间分析
对每个簇进行时间序列分析,判断是否为用户停留的区域。
检查时间连续性
def is_staying(cluster_points, time_threshold=2):
points = sorted(cluster_points, key=lambda p: p[2])
for i in range(1, len(points)):
if points[i][2] - points[i-1][2] > time_threshold:
return False
return True
应用到每个簇
for cluster in range(kmeans.n_clusters):
cluster_points = [data[i] for i in range(len(data)) if labels[i] == cluster]
if is_staying(cluster_points):
print(f"Cluster {cluster} is likely a staying area.")
else:
print(f"Cluster {cluster} is not a staying area.")
4. 综合判断
结合空间和时间因素,筛选出用户可能停留的区域。
优化聚类参数
- 调整K值:根据数据分布选择合适的聚类数。
- 调整时间阈值:根据用户停留时间动态调整时间间隔阈值。
可视化结果
import matplotlib.pyplot as plt
# 绘制聚类结果
plt.scatter(X, Y, c=labels, cmap='viridis')
plt.colorbar(label='Cluster')
plt.title('Clustered Mouse Movement')
plt.show()
5. 进一步优化
- 滑动窗口合并连续点:将连续的鼠标移动点合并为一个点,减少噪声。
- 时空聚类算法:使用时空聚类库(如
spatio-temporal)直接处理时间序列。 - 动态阈值:根据用户停留时间动态调整时间阈值。
示例输出
Cluster 0 is likely a staying area.
Cluster 1 is not a staying area.
Cluster 2 is likely a staying area.
注意事项
- 噪声处理:去除异常点(如突然的移动)。
- 时间窗口:滑动窗口可减少噪声,提高聚类准确性。
- 参数调优:通过交叉验证调整聚类参数(如K值、时间阈值)。
总结
通过空间聚类(如KMeans或DBSCAN)和时间分析,可以识别用户在屏幕上的兴趣区域。结合时间连续性判断,可有效筛选出用户停留的区域。最终结果需结合可视化和实际数据验证。
微调后的 Qwen3-1.7B 模型呈现出一种结构严谨、任务导向明确的专业技术讲解风格。模型在PPO-RW强化学习对齐后,结构化知识输出显著增强,呈现出完整的技术教程框架,能直接给出明确技术选择,聚焦可立即执行的实操步骤,模型回答风格更专业、自信。代码生成质量进一步提升,覆盖从读数据到可视化的完整链路,技术解释更深入,能围绕用户意图给出拓展建议。
总结
用户可通过LlamaFactory Online平台预置的模型及数据集完成快速微调与效果验证,本实践完成了一次成功的模型微调。微调后的Qwen3-1.7B模型给出的解答结构完整,逻辑清晰,结论明确,能够生成更具实操化、工程化视角突出的高质量内容,证明了该技术路径在应用层面的巨大价值。