微调基于Qwen3-Omni-30B-A3B-Instruct的私人导览专家
当文化消费成为假日生活的核心选择,十一黄金周的博物馆观展热潮已成为社会文化新景观,亲子研学、深度文化体验需求的激增,让传统博物馆导览服务面临严峻考验。在人头攒动的展厅中,人工讲解员资源紧张且接待量有限,多数游客难以获得针对性讲解;传统语音导览器则深陷内容固定、交互僵化的困境,既无法响应个性化疑问,也难以建立知识关联,最终导致大量游客陷入 “走马观花” 的尴尬,仅能目睹展品外观,却对其背后的历史脉络、文化内涵与艺术价值一知半解。
Qwen3-Omni-30B-A3B-Instruct模型作为阿里推出的新一代全模态基础模型,Qwen3-Omni从预训练阶段便实现文本、图像、音频、视频的端到端混合训练,其原生具备的 119 种文本语言支持、19 种语音输入理解能力,与毫秒级响应速度的交互体验,天然契合博物馆多场景导览需求。更值得关注的是,该模型采用 MoE-based Thinker–Talker 架构,通过思考与表达模块的协同,可实现低延迟流式交互,配合 Apache 2.0 开源协议带来的灵活定制性,为文博场景的适配提供了技术可能。
基于Qwen3-Omni-30B-A3B-Instruct模型打造专属 “智能博物官”,借助 LlamaFactory Online 平台的高效微调能力,融入文博领域专属的多模态指令数据,可让 Qwen3-Omni 精准适配观展场景:从识别青铜器铭文的视觉问答,到解析瓷器釉色工艺的语音追问,再到跨朝代审美对比的知识延伸,将通用智能转化为专业导览能力。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Qwen3-Omni-30B-A3B-Instruct | 是 | 经过指令微调,参数量约305亿(30.5B),单步推理时激活约30亿 (3B) 参数,能够无缝处理文本、图像、音频和视频,并同时生成文本和自然语音回复。 |
| 数据集 | alpaca_museum_multimodal | 否(提供下载链接) | 包含丰富的文物图像、详细的文本描述以及相关的知识图谱信息。 |
| GPU | H800*1(推荐) | - | - |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
使用推荐资源(H800*1)进行微调时微调过程总时长约2h18min。
数据准备
单击链接下载数据集,然后上传至文件管理。具体操作,可参考SFTP上传下载完成数据集上传。
操作详情
安装llamafactory
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
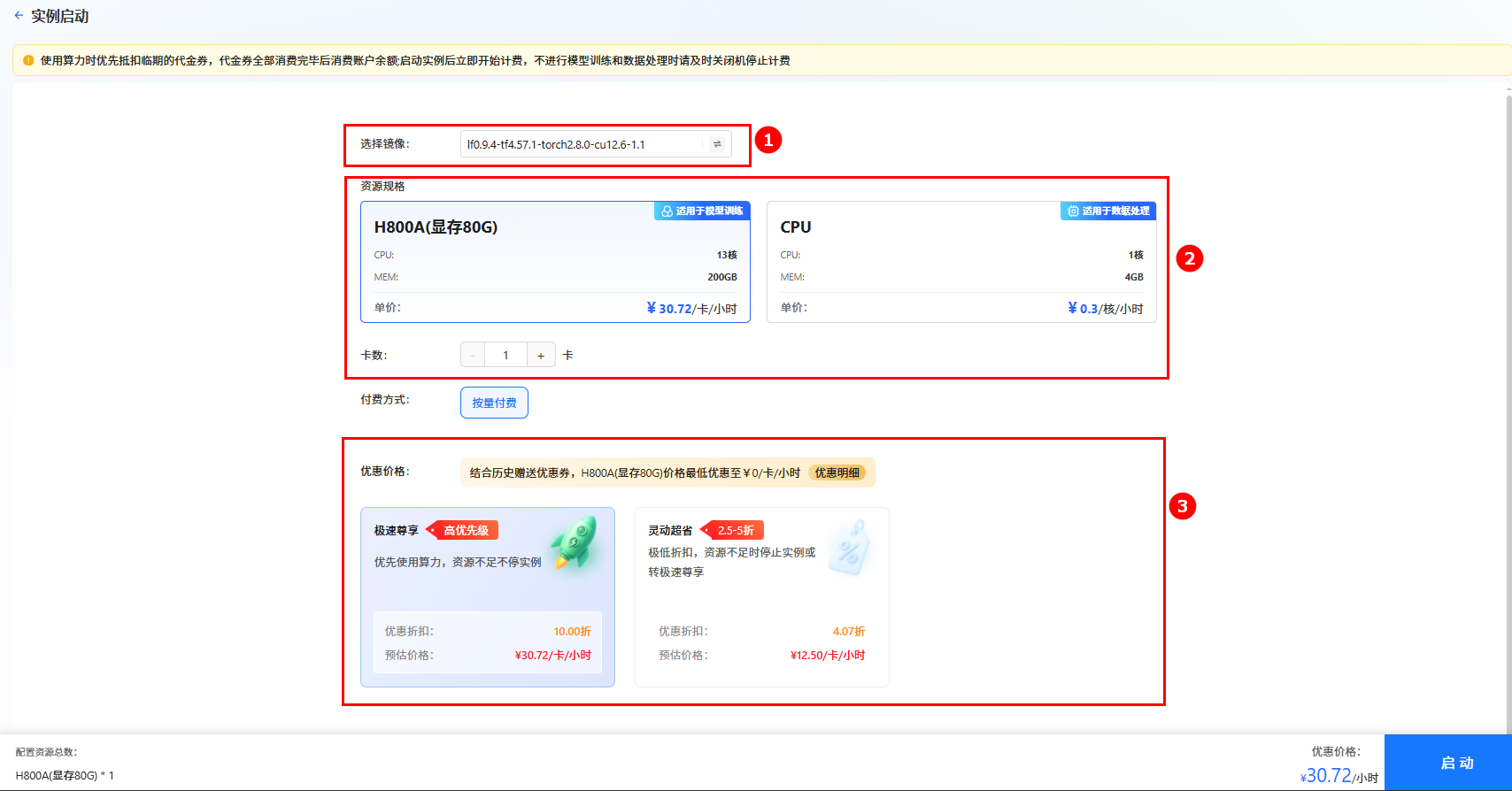
单击上图“开始微调”按钮,进入[实例启动]页面,配置以下参数,然后单击“启动”按钮,启动实例。
- 选择镜像:系统默认镜像
lf0.9.4-tf4.57.1-torch2.8.0-cu12.6-1.1(如图①)。 - 资源配置:选择GPU,推荐卡数为1卡(如图②)。
- 选择价格模式:本实践选择“极速尊享”(如图③),不同模式的计费说明参考计费说明。
 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
- 选择镜像:系统默认镜像
-
实例启动后,可启动VSCode或者JupyterLab专属数据处理,本次实践我们使用JupyterLab专属数据处理。
-
创建并配置用于数据处理的python环境。在JupyterLab中单击“Terminal”进入终端。
执行如下命令,创建一个虚拟环境,python版本选择3.12。
conda create -n omini python=3.12 -y
conda activate omini -
执行如下命令,下载安装llamafactory。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation安装完成后:
a. 执行如下命令,安装支持Omini模型的Transform和accelerate版本。
pip install git+https://github.com/huggingface/transformers
pip install accelerateb. 单击链接下载flashatten,选择“flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp312-cp312-linux_x86_64”版本进行下载。
下载完成后上传至/workspace目录下,并执行如下命令安装flashatten。
pip install /workspace/flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp312-cp312-linux_x86_64.whlc. 替换llamafactory源码文件,单击下载loader.py文件,并放至
/workspace/LLaMA-Factory/src/llamafactory/data/目录下进行替换。 -
启动llamafactory服务,可以通过6666端口号启动。
GRADIO_SERVER_PORT=6666 llamafactory-cli webui -
访问llamafactory服务。通过对外服务网址进行llamafactory的访问。
模型训练
-
在微调页面,配置如下参数:
- 模型选择:
Qwen3-Omni-30B-A3B-Instruct,如图①; - 模型路径:在预置路径前加上
/shared-only/models/,如图②。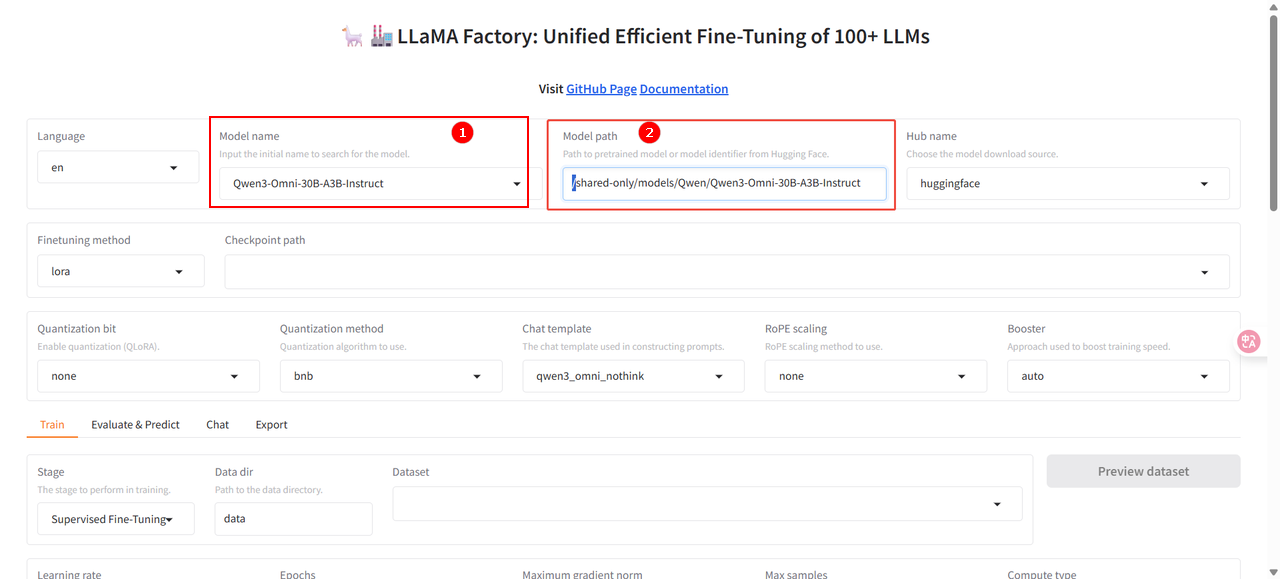
- 模型选择:
-
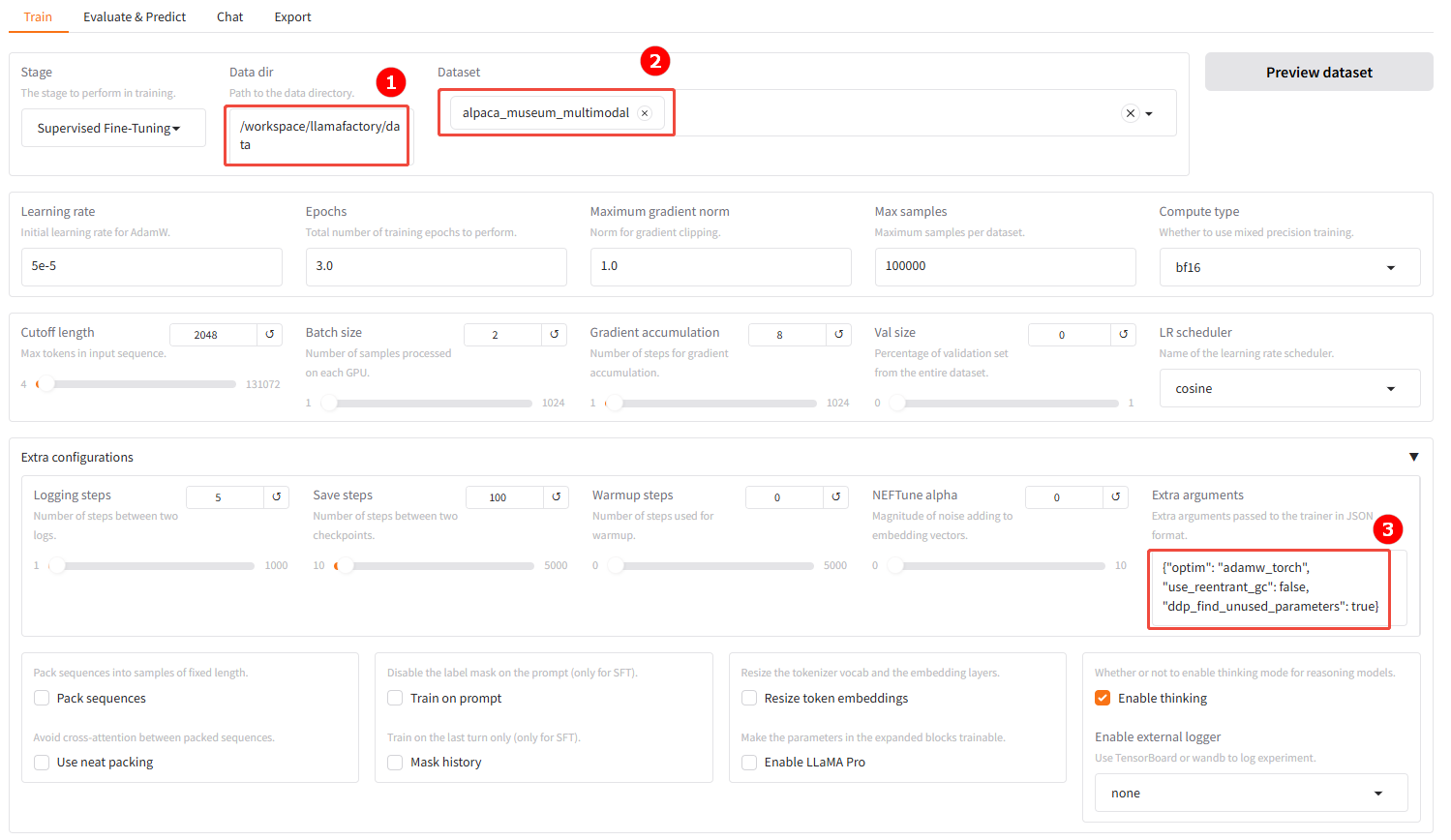
修改数据集路径,并加载数据集。
-
数据集路径:设置为
/workspace/llamafactory/data,如图①; -
数据集:选择数据集
alpaca_museum_multimodal,如图②; -
Extra arguments:需要设置
use_reentrant_gc和ddp_find_unused_parameters,即设置为{"optim": "adamw_torch", "use_reentrant_gc": false, "ddp_find_unused_parameters": true},如图③。注意- 如果模型有条件分支,保留
find_unused_parameters=True; - 如果PyTorch ≥ 2.1,建议固定
use_reentrant_gc=False; - 若模型固定结构(无条件分支),可以关掉两者以获取更好性能。
- 如果模型有条件分支,保留
-
-
单击“开始(Start)”,启动微调。
 提示
提示- 训练的模型权重文件保存在
/workspace/saves目录下,训练完成后可以在对应目录下找到模型文件。 - 启动微调后,您可以使用
nvidia-smi命令实时查看GPU使用情况(包括占用率、显存使用、进程等)。
训练完成后如下图所示。
- 训练的模型权重文件保存在
模型对话
-
切换到对话(Chat)页面,进行对话。
a. 单击“chat”页签(如图①),然后直接单击“加载模型(Load model)”按钮(如图②),加载原生模型。

b. 使用原生模型进行对话。上传一张博物馆藏图片(如图①),并且输入您的问题(如图②),然后单击“提交(Submit)”(如图③)。
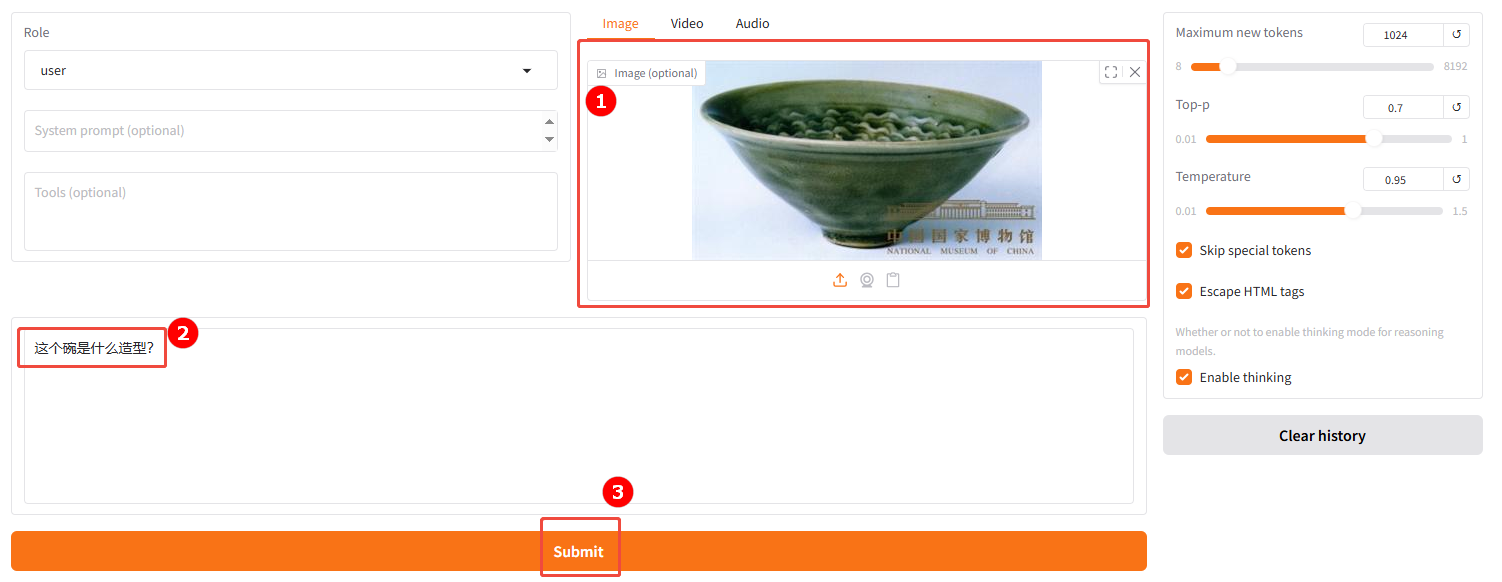
微调前的模型回答如下:
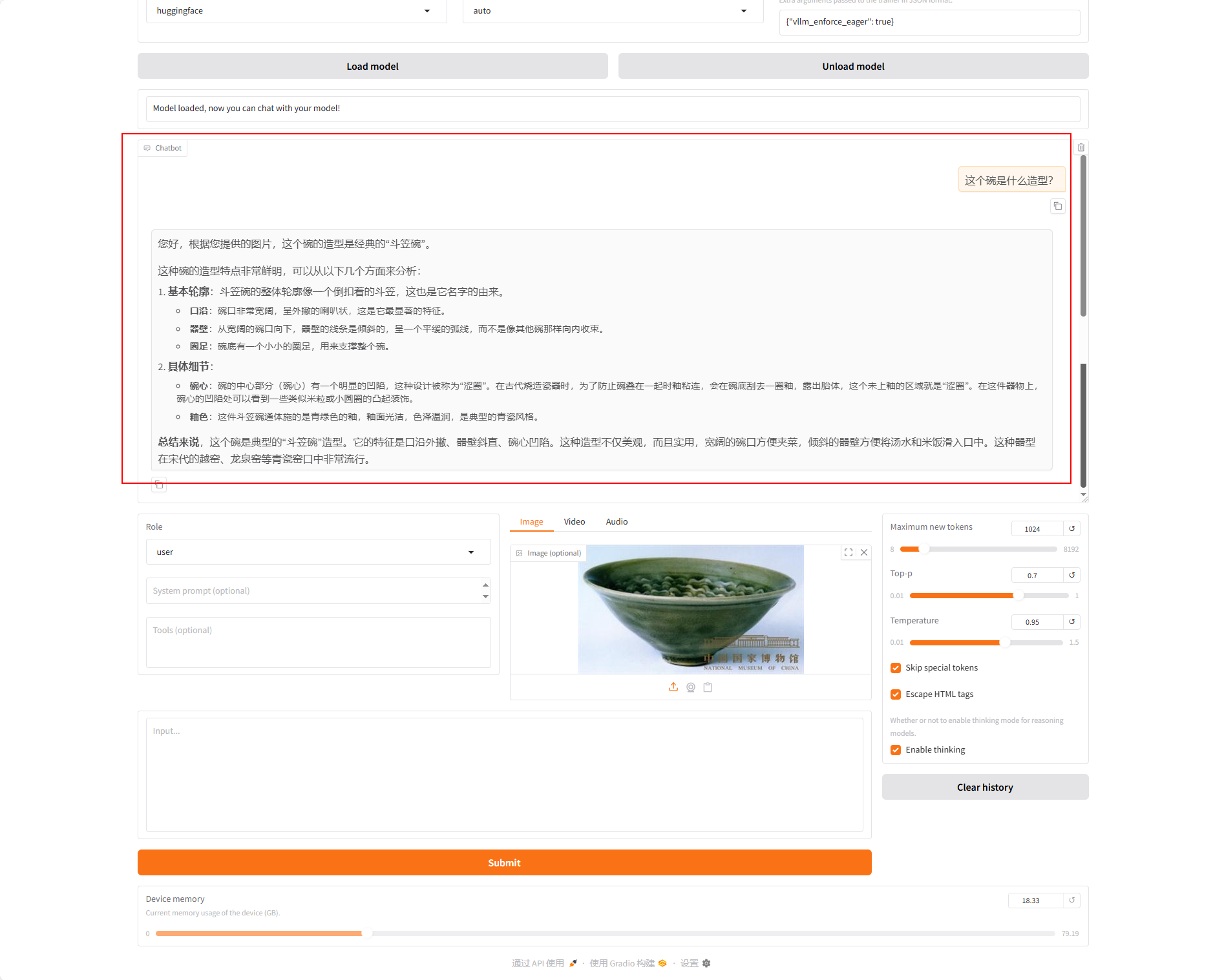
c. 使用加载好的微调模型进行对话。单击“加载模型”按钮,加载微调后的模型,输入同一个问题,观察模型回答,示例如下图所示。
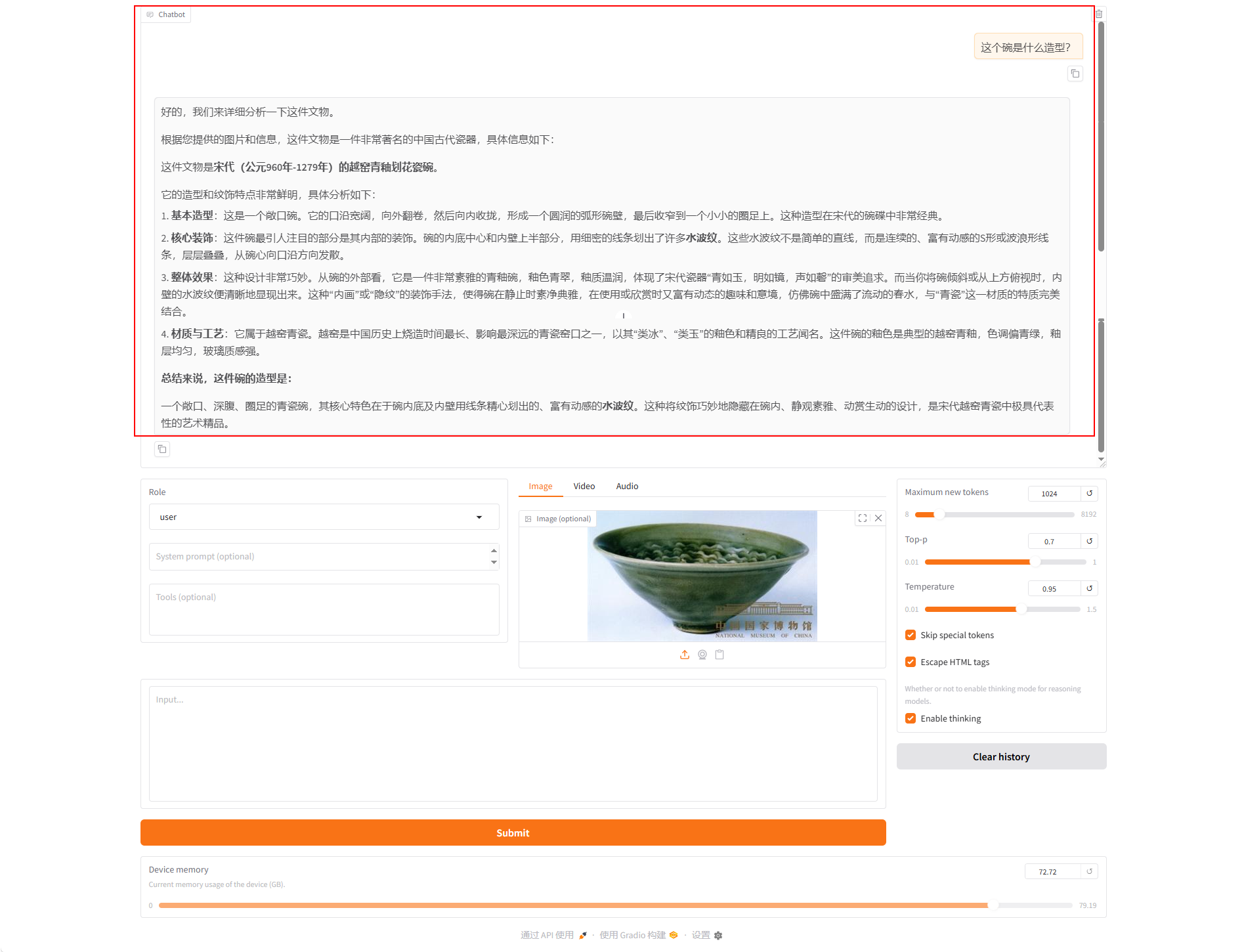
综合来看,利用微调后的模型开展对话,能得到更具参考价值的回答。和原生模型不同,原生模型常给出宽泛、笼统的可能性描述,而经特定任务或数据集微调的模型,能结合实际图片场景生成更精准、更有针对性的内容。此处仅用少量数据演示技术路线与操作流程,若您追求更好效果,可使用约5000条自身的文旅数据来进行微调。
总结
基于Qwen3-Omni-30B-A3B-Instruct模型微调,让每一位游客都能拥有 “私人文化顾问”:无需争抢资源,不必受制于固定流程,只需通过拍摄、语音等自然交互方式,便能获得深度、连贯且个性化的文化解读。这既是对十一黄金周博物馆服务压力的精准纾解,更是对 “从信息传递到文化共鸣” 的智能导览演进方向的生动实践,让文化遗产的魅力在科技赋能下真正触达人心。