构建基于Qwen3-vl-30B-A3B-Instruct的医疗影像微调实战
Qwen3-vl-30B-A3B-Instruct模型是Qwen3系列开源的新一代多模态视觉语言模型。作为Qwen家族迄今最强的视觉语言模型,Qwen3-vl在保持纯文本能力的同时,将视觉理解指标推向了新高度。Qwen3-vl-30B-A3B-Instruct通过引入3B激活参数的稀疏架构,在仅激活30亿参数的情况下即可在STEM、VQA、OCR、视频解析及Agent任务上对标甚至超越GPT-5-Mini与Claude4-Sonnet,同时保持30B总参数量的稀疏激活能力,实现性能与效率的平衡。
当前通用多模态视觉语言模型在医疗影像场景中存在显著技术瓶颈:高分辨率医学影像(如CT、MR)的细粒度特征提取能力不足,且模型推理时显存占用高、计算效率低,难以支撑临床实时分析与大规模部署需求。我们可以通过LlamaFactory Online平台,利用MedTrinity-25M子集(16K样本)对Qwen3-vl-30B-A3B-Instruct进行LORA微调,验证“小数据+稀疏激活”在医疗多模态场景的落地效果。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。单击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Qwen3-vl-30B-A3B-Instruct | 是 | 稀疏激活,仅3B参数激活,支持高分辨率动态切换。 |
| 数据集 | train-00000-of-00010.parquet | 否(提供下载链接) | 选取的数据集是MedTrinity-25M子集中的其中一个(16163张图片),MedTrinity-25M是当前规模最大的公开医学影像-文本对数据集,涵盖CT、MR、X-Ray等多种模态,为医疗多模态模型的训练与评估提供了丰富燃料。 |
| GPU | H800*4(推荐) | - | 模型规模较大,建议配置足够显存。 |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
- 模型微调时长
- 微调后的模型Evaluate & Predict时长
- 原生模型Evaluate & Predict时长
操作步骤
步骤一:数据准备
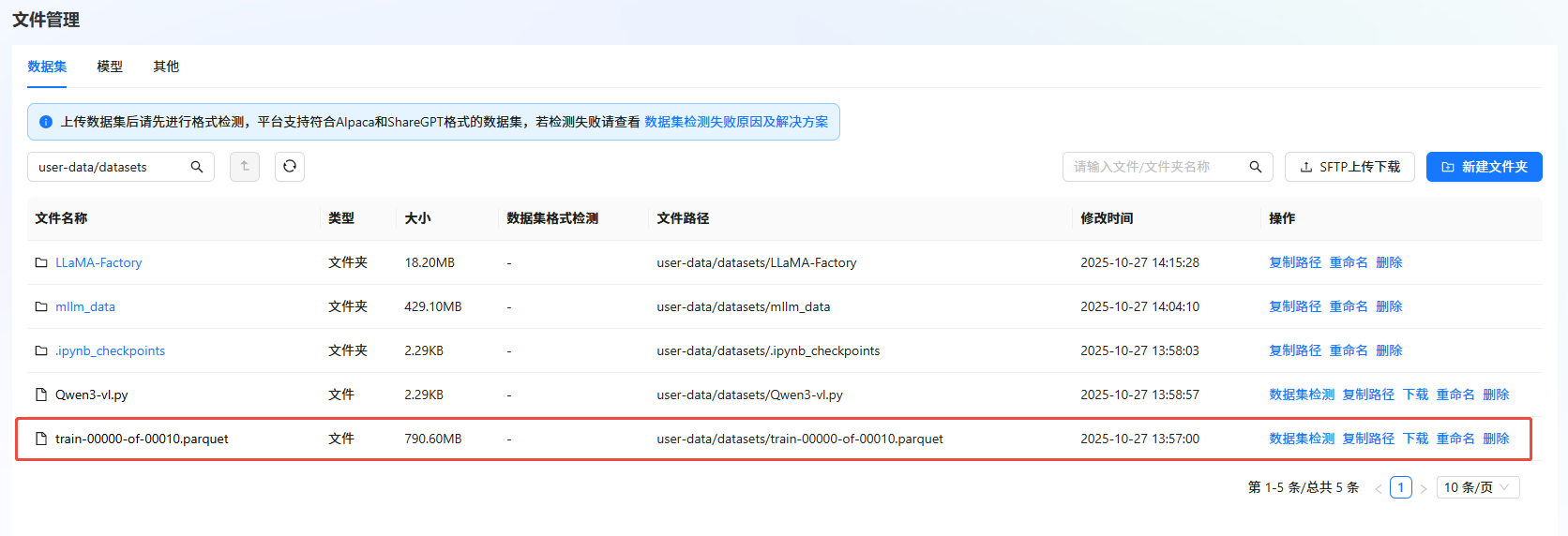
-
单击链接,下载train-00000-of-00010.parquet数据集。数据集下载完成后,需上传至文件管理。具体操作,可参考SFTP上传下载完成数据集上传。
-
数据格式转换。
LlamaFactory作为主流的大语言模型微调框架,对医疗问诊类数据有明确的格式要求。因此需将原数据格式转换为LLaMA Factory兼容的数据格式。数据格式转换的具体步骤如下:
a. 进入LlamaFactory Online平台,单击“控制台”,进入控制台后单击左侧导航栏的“实例空间”,然后在页面单击“开始微调”。
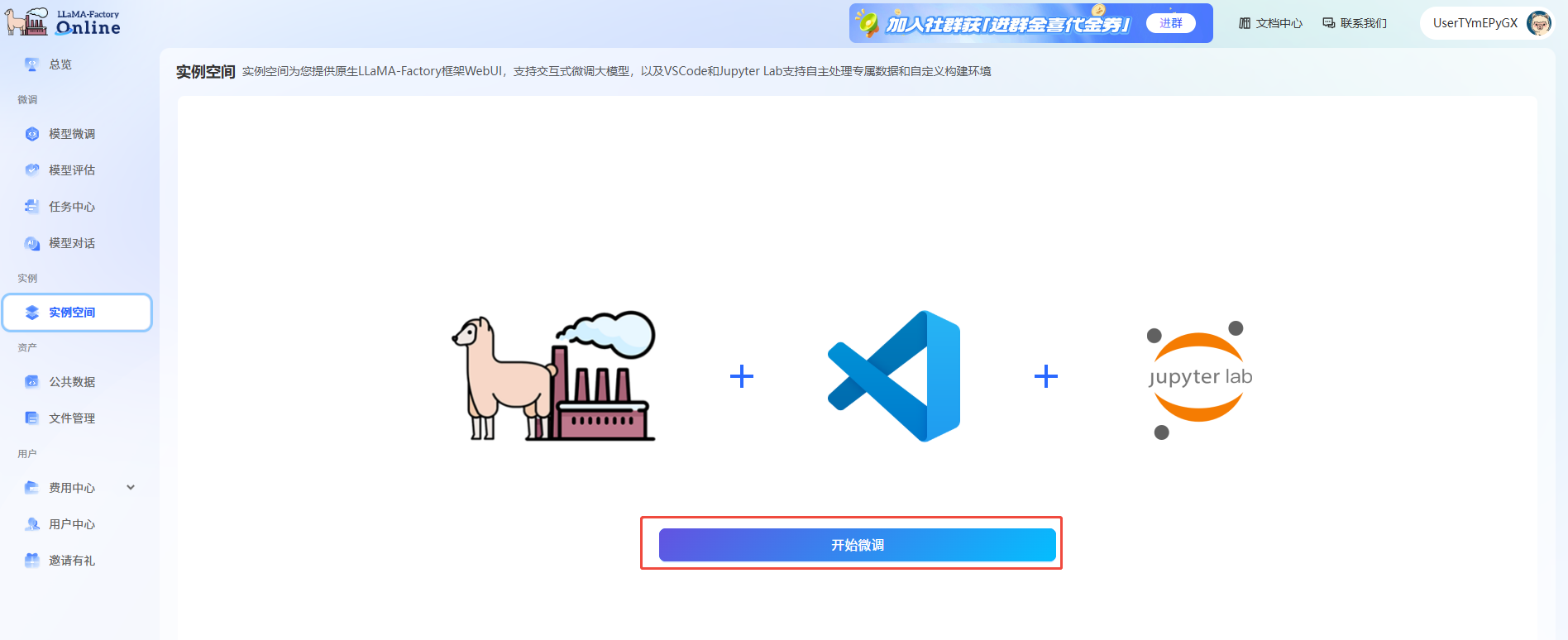
b. 在弹出的页面选择镜像(如图①),选择“CPU”,核数选择“2核”(如图②),然后单击“启动”。
 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
c. 实例启动后,单击[VSCode处理专属数据]页签,进入VSCode编辑页面。您也可以根据需要打开JupyterLab处理专属数据,本示例指导您通过VSCode处理数据。
d. 在VSCode页面左侧user-data/datasets目录下(如图①)新建一个.py后缀的文件(如图②),然后复制以下命令至文件中(如图③)。
代码详情
#多模态数据格式转换代码
import os
import json
import random
from tqdm import tqdm
import datasets
def save_images_and_json(ds, ratio=0.1, output_dir="mllm_data"):
"""
保存数据集中的图像,并且构建多模态训练集和验证集。
参数:
ds: 数据集对象,包含图像和描述。
ratio: 验证集比例,默认为 0.1。
output_dir: 输出目录,默认为 "mllm_data"。
"""
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
all_train_data = [] # 多模态训练数据
all_val_data = [] # 多模态验证数据
total_samples = len(ds)
val_index = set(random.sample(range(total_samples), int(ratio * total_samples)))
# 遍历数据集中的每个项目
for idx, item in tqdm(enumerate(ds), total=total_samples, desc="Processing"):
img_path = os.path.join(output_dir, f"{item['id']}.jpg")
image = item["image"]
# 保存图像
image.save(img_path)
sample = {
"conversations": [
{
"from": "user",
"value": "<image>图片中的诊断结果是怎样?"
},
{
"from": "assistant",
"value": item["caption"] # 从数据集中获取的描述
}
],
"images": [img_path] # 图像文件路径
}
if idx in val_index:
all_val_data.append(sample)
else:
all_train_data.append(sample)
# 将数据保存到 JSON 文件
train_json_path = os.path.join(output_dir, "mllm_train_data.json")
val_json_path = os.path.join(output_dir, "mllm_val_data.json")
with open(train_json_path, "w", encoding="utf-8") as f:
json.dump(all_train_data, f, ensure_ascii=False, indent=2)
with open(val_json_path, "w", encoding="utf-8") as f:
json.dump(all_val_data, f, ensure_ascii=False, indent=2)
if __name__ == "__main__":
# 加载数据集
ds = datasets.load_dataset("parquet", data_files="/workspace/user-data/datasets/train-00000-of-00010.parquet")["train"]
# 保存图像并构建多模态训练/验证集
save_images_and_json(
ds,
ratio=0.2,
output_dir="/workspace/user-data/datasets/mllm_data"
)
e. 在VSCode页面,新建一个终端,依次执行以下命令,进行数据格式转换(如图①)。
conda activate /opt/conda/envs/lf
python /workspace/user-data/datasets/Qwen3-vl.py提示Qwen3-vl.py为本示例新建的文件,请根据您的实际情况进行替换。
回显信息如图②所示,说明数据格式转换成功,且转换后的数据存放在/datasets/mllm_data中,即原数据集文件train-00000-of-00010.parquet经格式转换后生成新的数据集文件mllm_data(如图③),其中包括mllm_train_data.json和mllm_val_data.json数据集文件。

-
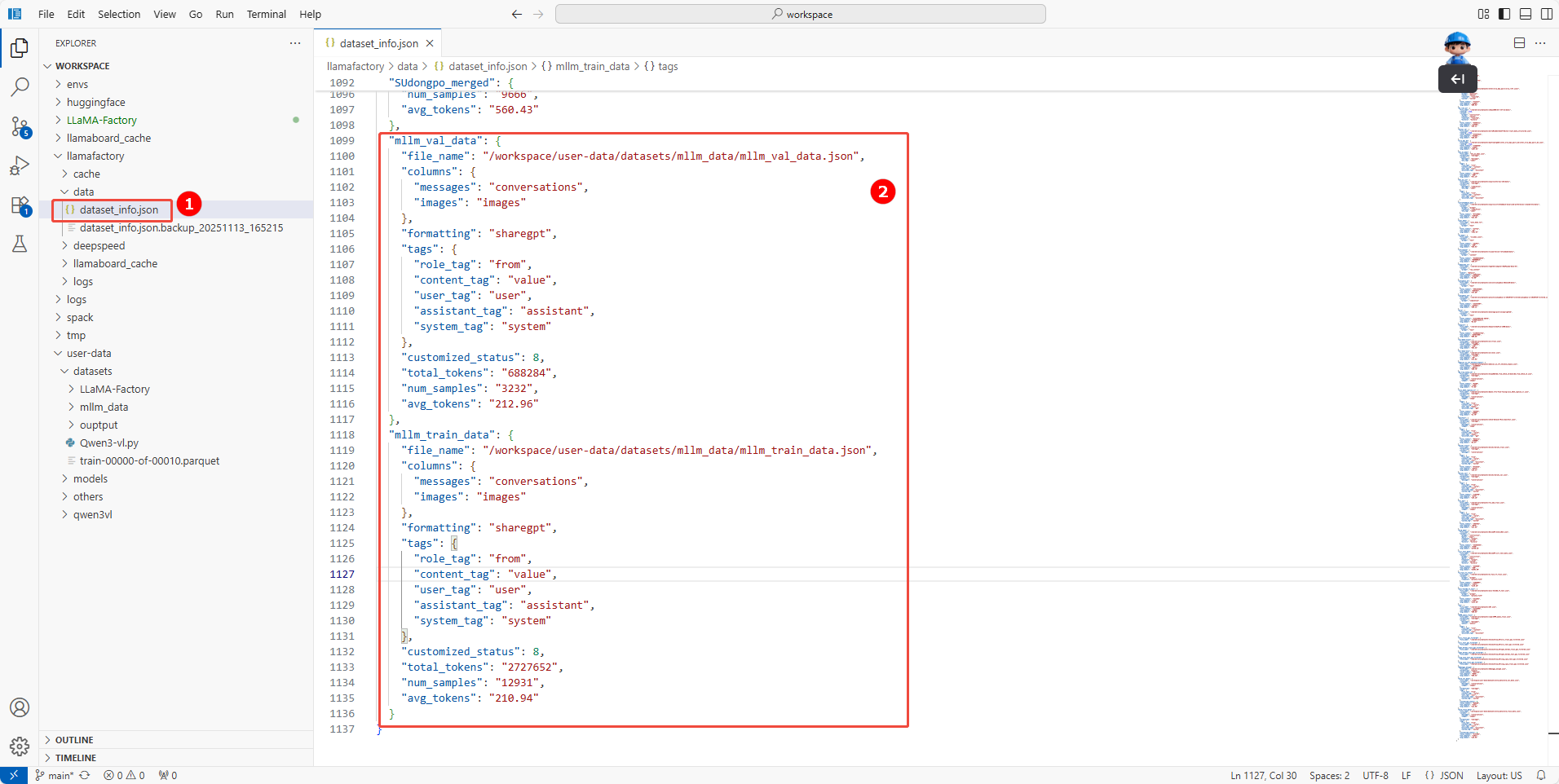
数据集注册。
在/workspace/llamafactory/data/dataset_info.json配置文件中(如图①),配置如下内容,注册数据集mllm_train_data.json和mllm_val_data.json(如图②)。
注册数据集mllm_train_data.json
"mllm_train_data": {
"file_name": "/workspace/user-data/datasets/mllm_data/mllm_train_data.json",
"columns": {
"messages": "conversations",
"images": "images"
},
"formatting": "sharegpt",
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
},
"customized_status": 8,
"total_tokens": "2727652",
"num_samples": "12931",
"avg_tokens": "210.94"
}注册数据集mllm_val_data.json
"mllm_train_data": {
"file_name": "/workspace/user-data/datasets/mllm_data/mllm_train_data.json",
"columns": {
"messages": "conversations",
"images": "images"
},
"formatting": "sharegpt",
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
},
"customized_status": 8,
"total_tokens": "2727652",
"num_samples": "12931",
"avg_tokens": "210.94"
}
-
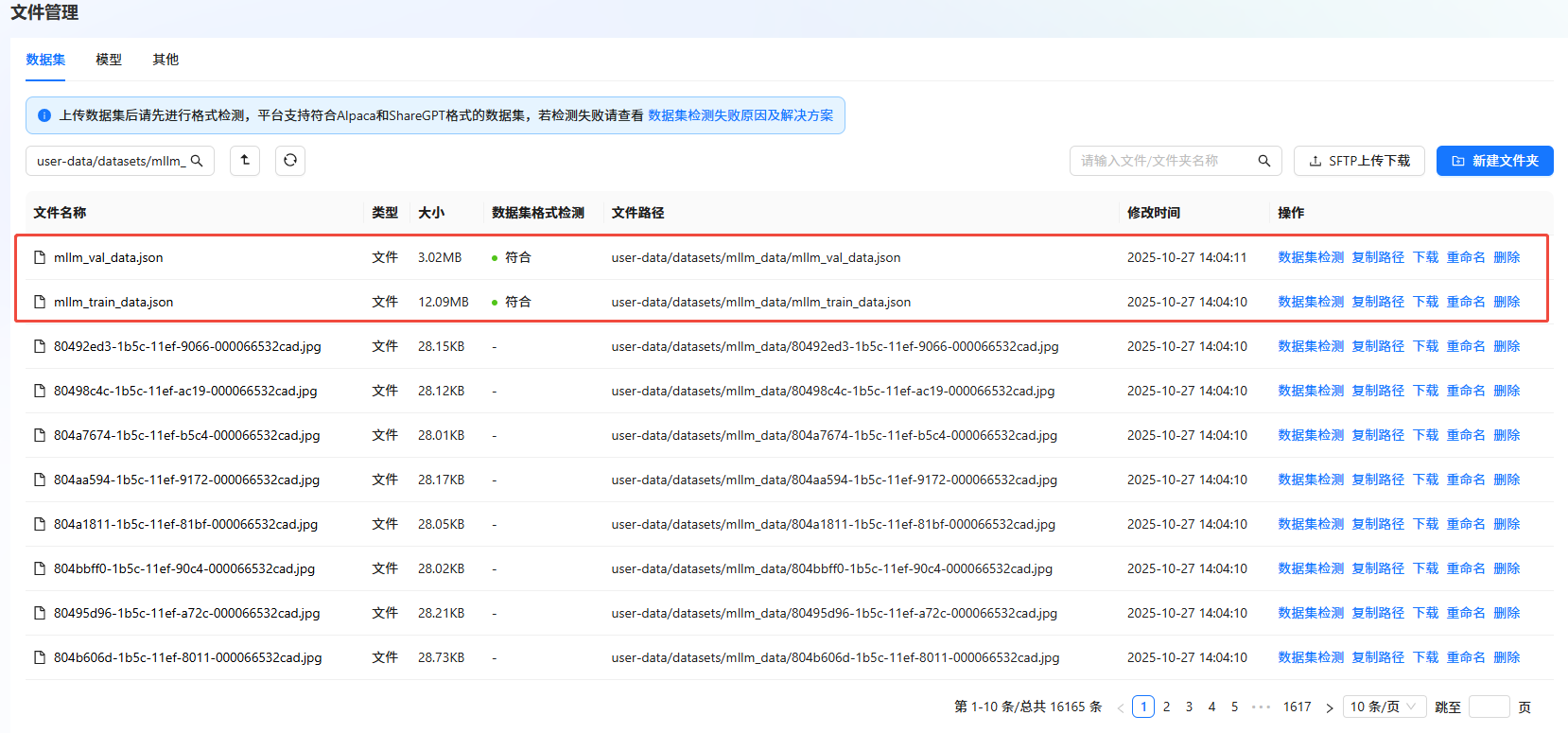
数据集检测。
a. 返回LlamaFactory Online控制台,单击左侧导航栏的“文件管理”。
b. 单击目标数据集右侧“操作”列的"数据集检测",检测数据集。如下图所示,若“数据集格式检测”结果显示“符合”,则表示数据集符合格式要求。
步骤二:模型训练
我们使用LlamaFactory Online通过任务模式和实例模式运行微调任务,不同模式下的微调/评估操作详情如下所示。
- 任务模式微调
- 实例模式微调
在任务模式下,我们对模型进行了两组微调实验(参数一和参数二),以评估不同配置的效果。两组实验的变量仅为 per_device_train_batch_size(32,4)和 DeepSpeed(3,2)参数,其他条件完全相同。具体参数差异如下表所示:
| 配置参数 | 参数说明 | 参数一 | 参数二 |
|---|---|---|---|
| 基础配置 | |||
| model | 训练用的基模型。 | Qwen3-VL-30B-A3B-Instruct | Qwen3-VL-30B-A3B-Instruct |
| dataset | 训练使用的数据集名称。 | mllm_train_data | mllm_train_data |
| stage | 训练方式 | sft | sft |
| finetuning_type | 微调方法 | lora | lora |
| 进阶配置 | |||
| LR Scheduling Type | 动态调整学习率的方式。 | cosine | cosine |
| Max Gradient Norm | 梯度裁剪的最大范数,用于防止梯度爆炸。 | 1.0 | 1.0 |
| 训练配置 | |||
| Learning Rate | 学习率 | 5e-05 | 5e-05 |
| Epochs | 训练轮数 | 2 | 2 |
| per_device_train_batch_size | 单GPU批处理大小。 | 32 | 4 |
| Gradient Accumulation | 梯度累计,将一个完整批次的梯度计算拆分为多个小批次,逐步累积梯度,最后统一更新模型参数。 | 8 | 8 |
| Save steps | 训练过程中每隔多少个训练步保存一次模型。 | 200 | 200 |
| Warmup Ratio | 将学习率从零增加到初始值的训练步数比例。 | 0 | 0 |
| Chat Template | 基模型的对话模版,训练和推理时构造prompt的模版。 | qwen3 | qwen3 |
| 效率与性能配置 | |||
| Mixed Precision Train | 混合精度训练,模型在训练或推理时所使用的数据精度格式,如 FP32、FP16 或 BF16。 | bf16 | bf16 |
| 分布式配置 | |||
| DeepSpeed | Deepspeed Stage是DeepSpeed中ZeRO(Zero Redundancy Optimizer)优化技术的阶段参数,其范围是none、2、3。参数越大,意味着模型状态的分片程度越高,每个GPU的内存占用越少,但同时通信开销也可能越大。 | 3 | 2 |
| 数据参数配置 | |||
| Max Sample Size | 每个数据集的最大样本数:设置后,每个数据集的样本数将被截断至指定的 max_samples。 | 100000 | 100000 |
| Cutoff Length | 输入的最大 token 数,超过该长度会被截断。 | 2048 | 2048 |
| Preprocess Workers | 预处理时使用的进程数量。 | 32 | 32 |
| 日志配置 | |||
| Logging Steps | 日志打印步数。 | 5 | 5 |
| LoRA配置 | |||
| Lora Rank | LoRA 微调的本征维数 r,r 越大可训练的参数越多。 | 8 | 8 |
| LoRA Scalling Factor | LoRA 缩放系数。一般情况下为 lora_rank * 2。 | 16 | 16 |
| Random dropout | LoRA 微调中的 dropout 率 | 0 | 0 |
| LoRA Modules | Lora作用模块 | all | all |
- 任务模式微调参数一
- 任务模式微调参数二
-
进入LlamaFactory Online平台,单击“控制台”,进入控制台后单击左侧导航栏的“模型微调”进入页面。
-
选择基础模型和数据集,进行参数配置。
- 本实践使用平台内置的Qwen3-VL-30B-A3B-Instruct作为基础模型,数据集选择文件管理处的
mllm_train_data。 - 其他参数配置选择上表中的参数一数据,具体可参考下图。
- 资源配置。推荐卡数为4卡。
- 选择价格模式。本实践选择“极速尊享”,不同模式的计费说明参考计费说明。
- 开始训练。单击“开始训练”按钮,开始模型训练。
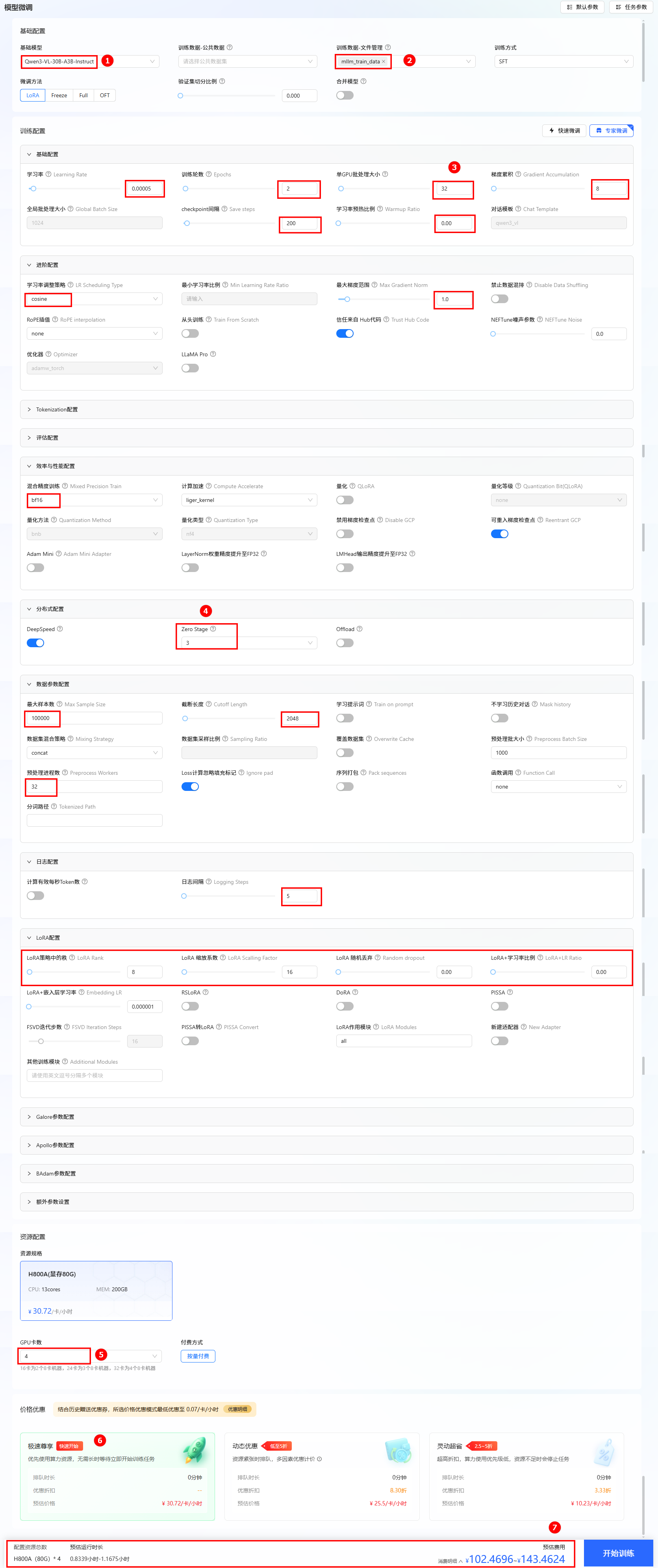 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
- 本实践使用平台内置的Qwen3-VL-30B-A3B-Instruct作为基础模型,数据集选择文件管理处的
-
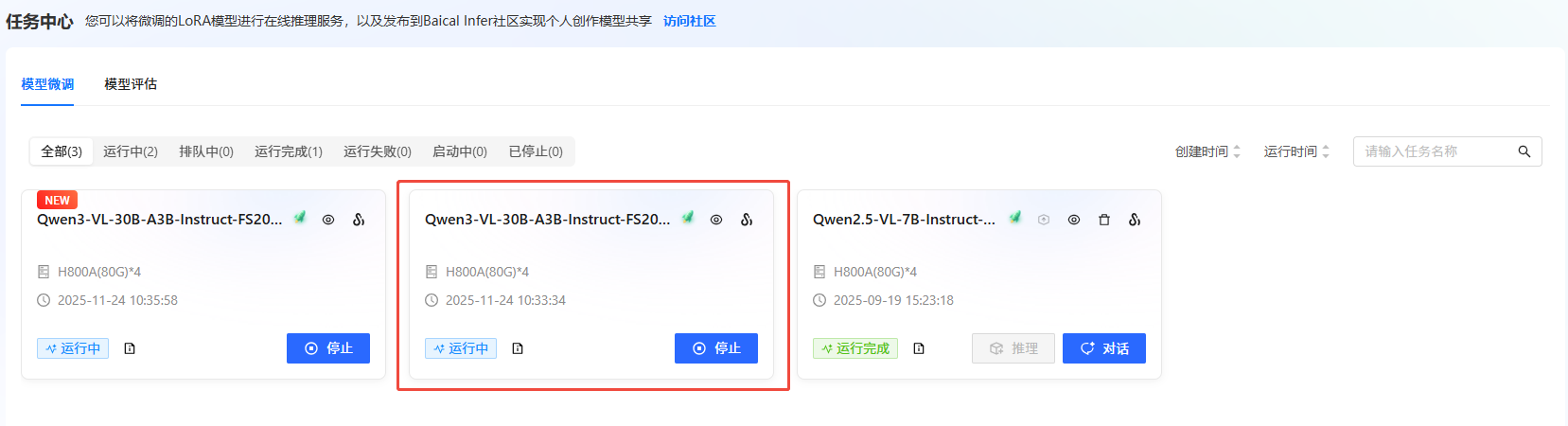
通过任务中心查看任务状态。 在左侧边栏选择”任务中心“,即可看到刚刚提交的任务。可以通过单击任务框,可查看任务的详细信息、超参数、训练追踪和日志。
-
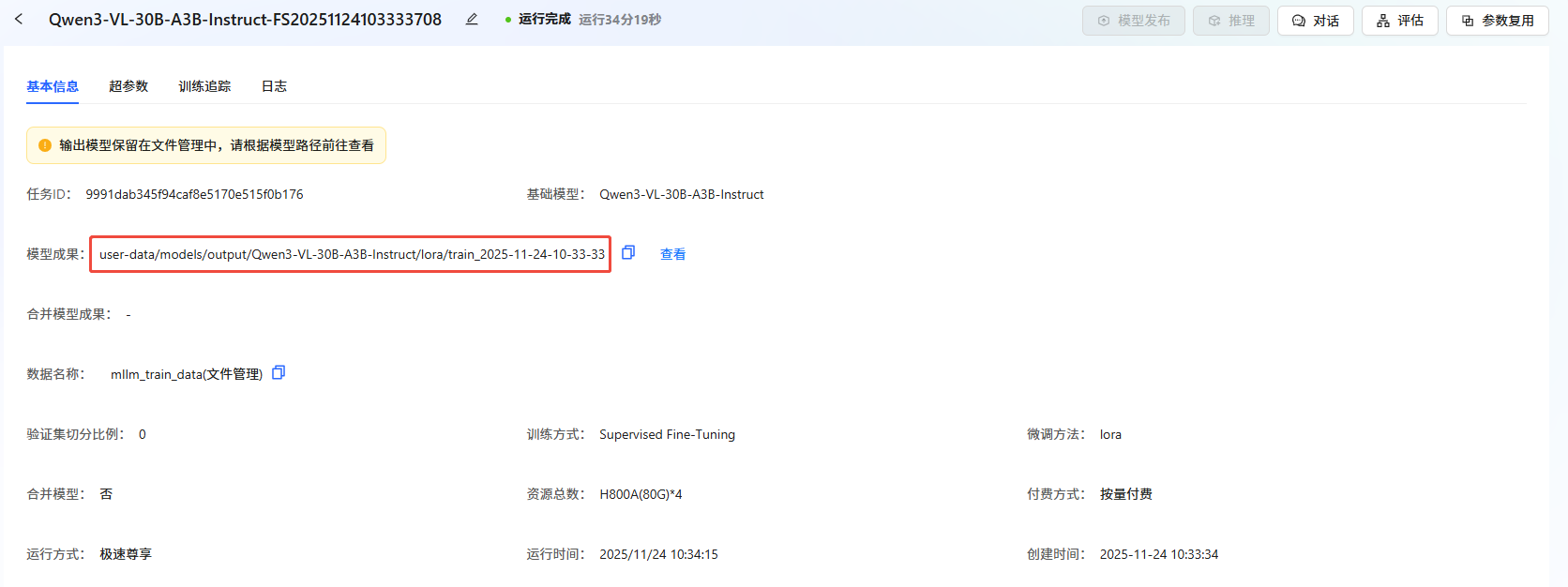
任务完成后,模型自动保存在"文件管理->模型->output"文件夹中。可在"任务中心->基本信息->模型成果"处查看保存路径。
 loss结果:
loss结果: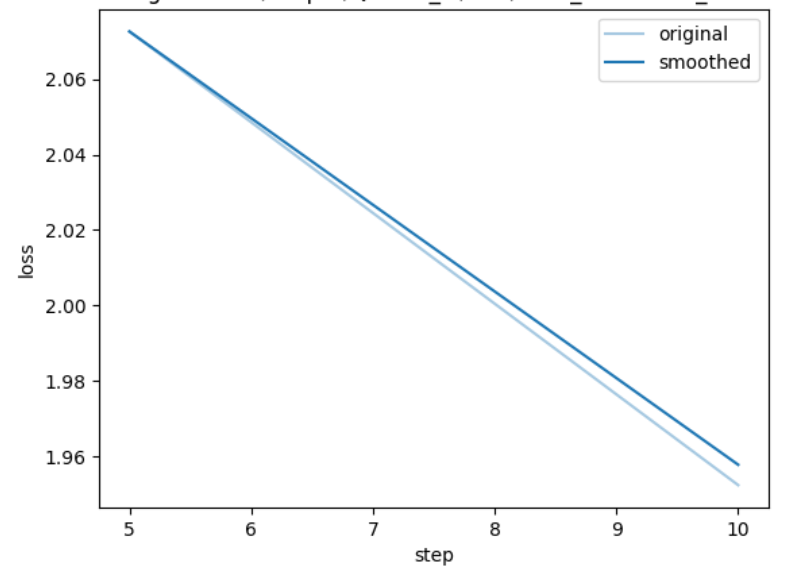
-
进行模型评估。 单击页面左侧导航栏“模型评估”,进行评估训练配置。 微调模型选择上一步骤微调后的模型,评估数据集选择文件管理处:
mllm_val_data。其他参数设置如下图所示。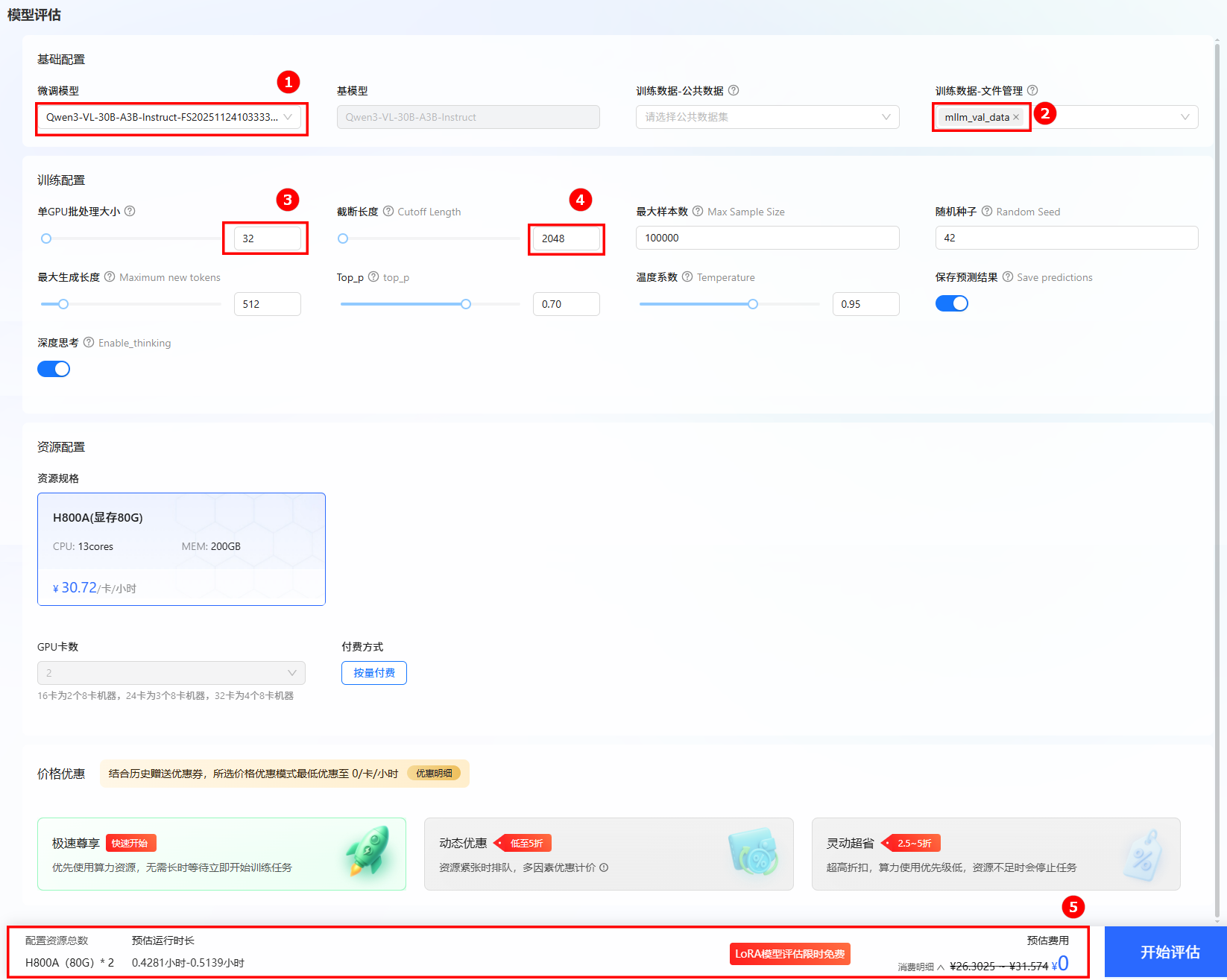 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
-
可以在“任务中心->模型评估”下看到评估任务的运行状态。

-
单击
 图标,进入任务基本信息查看页面。用户可查看评估任务的基本信息、日志,评估结束后,可查看评估结果如下图所示。
图标,进入任务基本信息查看页面。用户可查看评估任务的基本信息、日志,评估结束后,可查看评估结果如下图所示。
评估结果显示:其文本生成质量(BLEU/ROUGE 指标)处于中等水平,模型加载准备较快,但因参数规模大,运行总耗时极长、推理速度很低,整体呈现文本质量中等但运行效率偏低的特点。
-
模型对话。
a. 单击左侧导航栏“模型对话”按钮进入模型对话页面。
b. 在微调模型处选择步骤3中显示的模型名称(如图①)。单击右上角“开始对话”,在弹出的“LORA模型对话限时免费”对话框,单击“立即对话”。
c. 在输入框上传一张医疗影像图片(如图②),并输入问题(如图③),单击发送(如图④);在对话框中查看对话详情(如图⑤)。
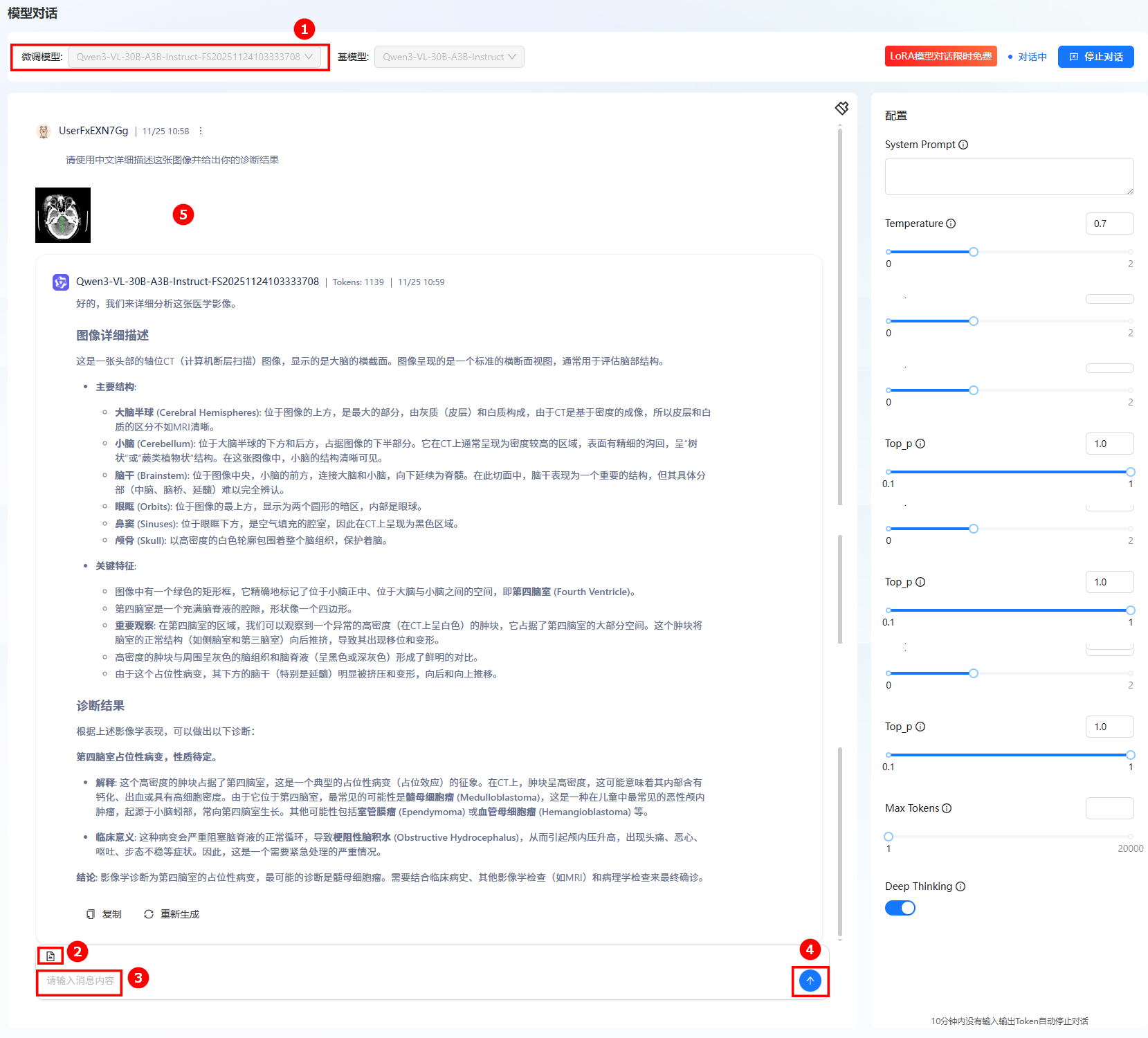
模型输出结果解读:这份分析专业覆盖了影像征象、病变风险与诊疗方向,是严谨的医学影像解读。
-
进入LlamaFactory Online平台,单击“控制台”,进入控制台后单击左侧导航栏的“模型微调”进入页面。
-
选择基础模型和数据集,进行参数配置。
- 本实践使用平台内置的Qwen3-VL-30B-A3B-Instruct作为基础模型,数据集选择文件管理处的
mllm_train_data。 - 其他参数配置选择上表中的参数二数据,具体可参考下图。
- 资源配置。推荐卡数为4卡。
- 选择价格模式。本实践选择“极速尊享”,不同模式的计费说明参考计费说明。
- 开始训练。单击“开始训练”按钮,开始模型训练。
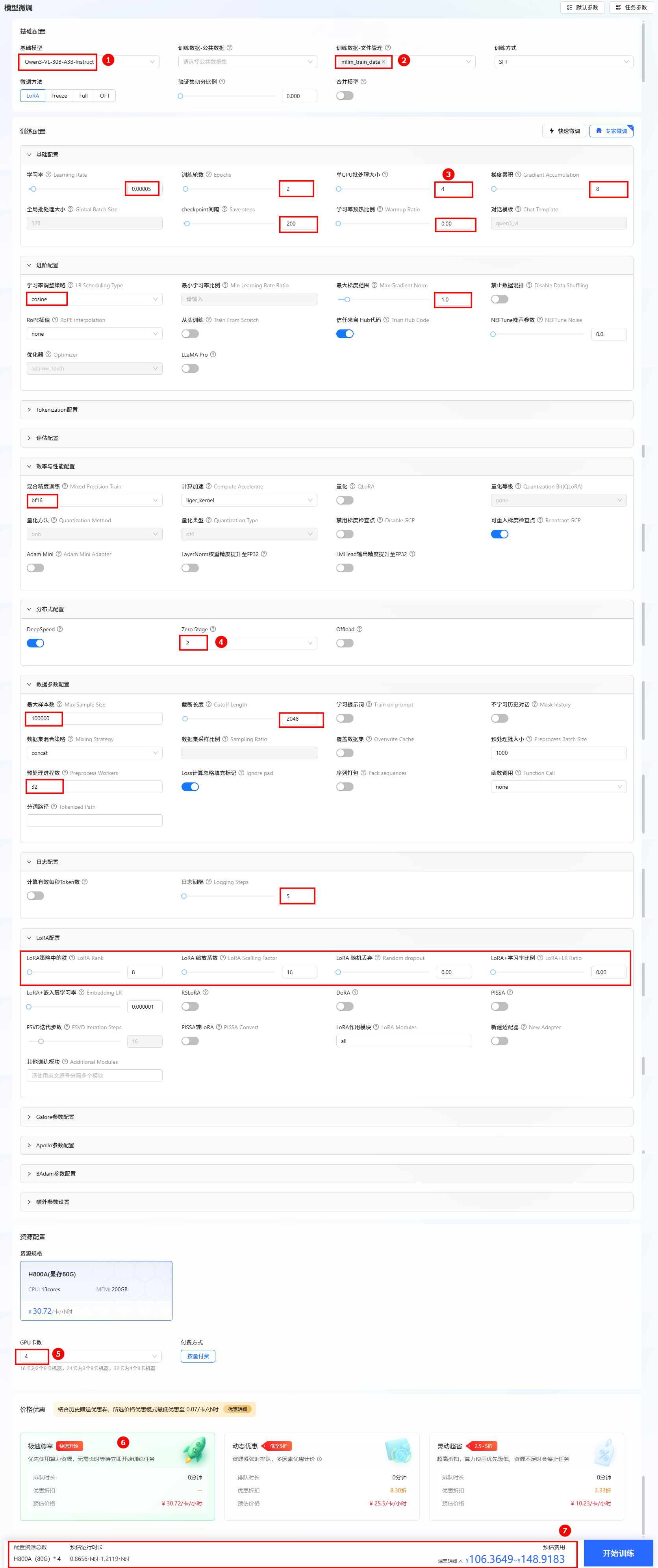 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
- 本实践使用平台内置的Qwen3-VL-30B-A3B-Instruct作为基础模型,数据集选择文件管理处的
-
通过任务中心查看任务状态。 在左侧边栏选择”任务中心“,即可看到刚刚提交的任务。可以通过单击任务框,可查看任务的详细信息、超参数、训练追踪和日志。
-
任务完成后,模型自动保存在"文件管理->模型->output"文件夹中。可在"任务中心->基本信息->模型成果"处查看保存路径。
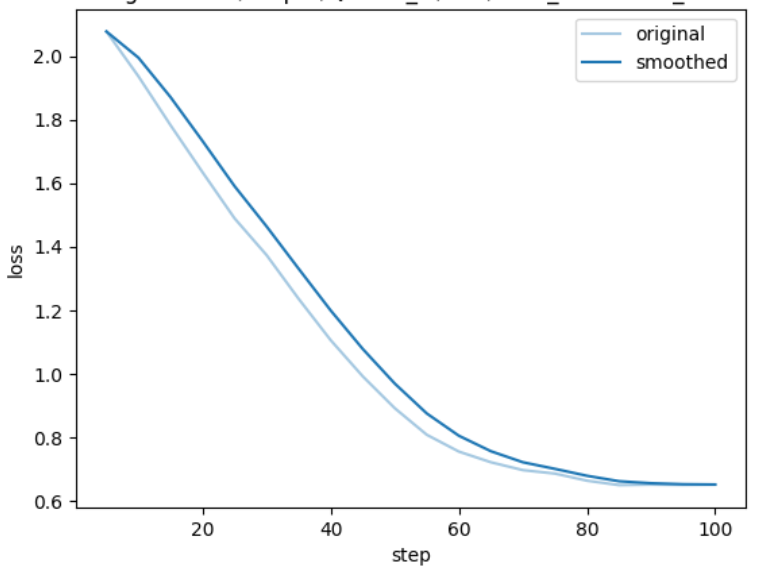
loss结果:
-
进行模型评估。 单击页面左侧导航栏“模型评估”,进行评估训练配置。 微调模型选择上一步骤微调后的模型,评估数据集选择文件管理处:
mllm_val_data。其他参数设置如下图所示。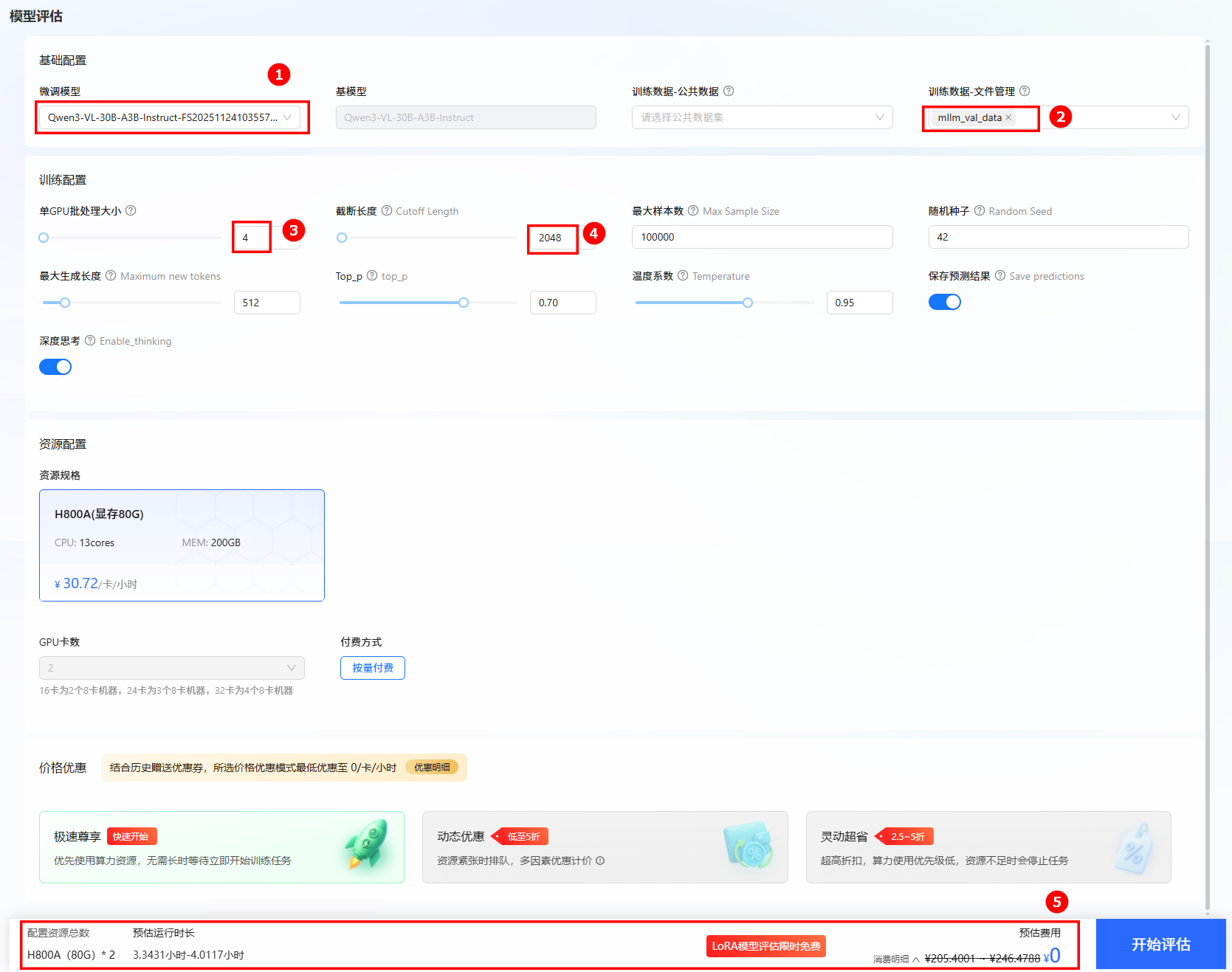 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
-
可以在“任务中心->模型评估”下看到评估任务的运行状态。

-
单击
图标,进入任务基本信息查看页面。用户可查看评估任务的基本信息、日志,评估结束后,可查看评估结果如下图所示。 评估结果:
评估结果显示:各项指标(BLEU-4 达 92.37、ROUGE 系列均超 94)都处于极高水平,说明生成文本与参考文本的内容重合度、连贯性、细节匹配度都非常好,文本生成质量属于优秀级别。运行效率有明显提升。
评估结果:
评估结果显示:各项指标(BLEU-4 达 92.37、ROUGE 系列均超 94)都处于极高水平,说明生成文本与参考文本的内容重合度、连贯性、细节匹配度都非常好,文本生成质量属于优秀级别。运行效率有明显提升。 -
模型对话。
a. 单击左侧导航栏“模型对话”按钮进入模型对话页面。
b. 在微调模型处选择步骤3中显示的模型名称(如图①)。单击右上角“开始对话”,在弹出的“LORA模型对话限时免费”对话框,单击“立即对话”。
c. 在输入框上传一张医疗影像图片(如图②),并输入问题(如图③),单击发送(如图④);在对话框中查看对话详情(如图⑤)。
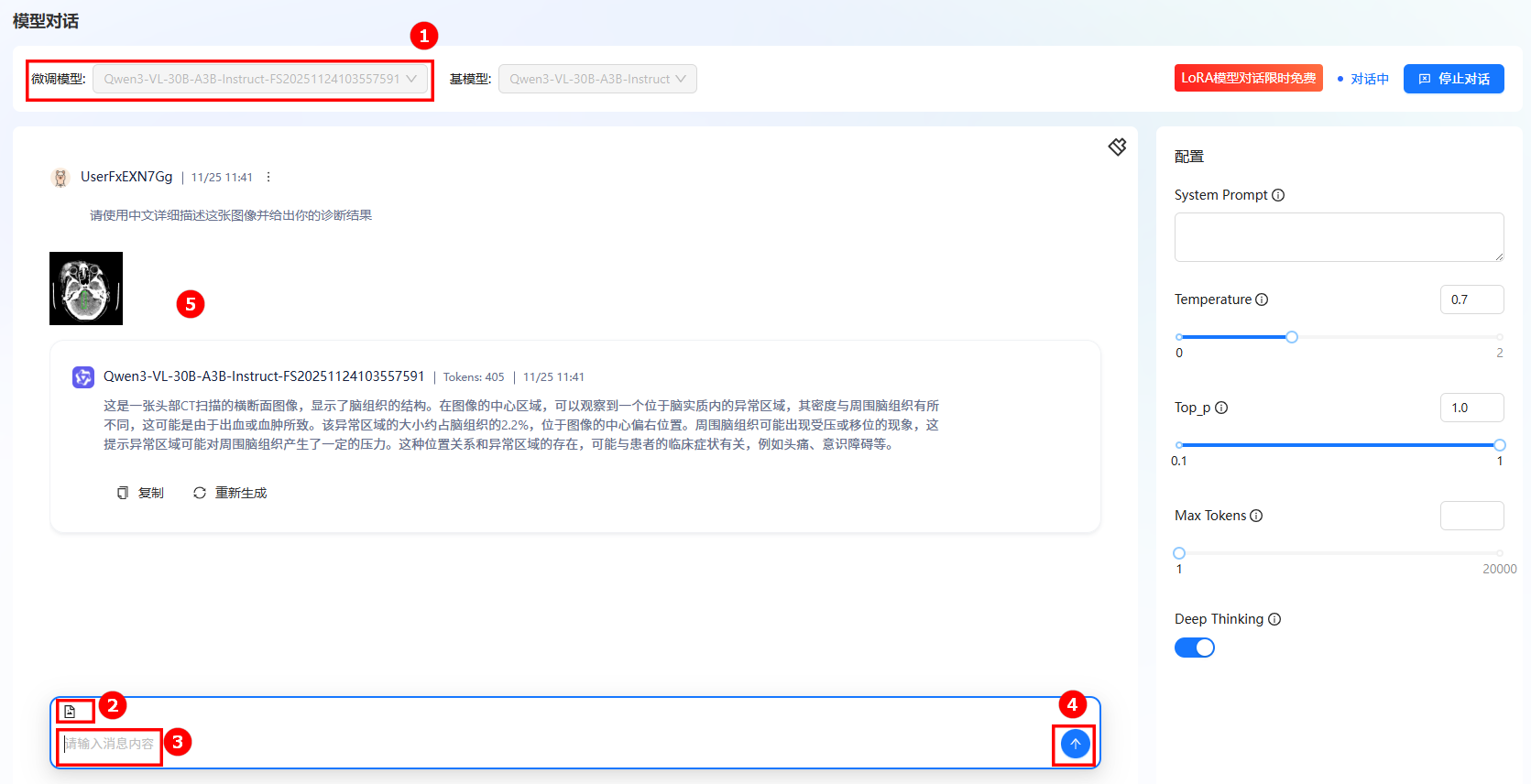
模型输出结果解读:这份分析专业覆盖了影像类型定位、核心异常征象、病理倾向推测与病变临床关联方向,是规范的基础医学影像辅助解读。
通过任务模式完成两组参数配置的模型微调后,从 loss 对比结果来看,相同硬件与数据集条件下,deepseed 3(参数一)方案训练速度更快,但微调阶段 loss 显著上升;deepseed 2(参数二)方案虽训练速度略有下降,却能更有效地压低 loss。具体来看:
- deepseed 3 训练速度的提升,核心得益于 “小块通讯 + 微批次自动放大” 带来的带宽优化;
- deepseed 3 微调 loss 上涨的本质,是 “参数延迟 + 梯度噪声” 导致模型收敛效果变差;
- 选型建议:若显存充足,优先选择 deepseed 2 方案以追求更优指标;若显存不足需使用 deepseed 3,则需同步通过放大 global batch、拉长 warmup 时长、降低学习率(lr)的方式弥补收敛性能。
| 参数一 | 参数二 |
|---|---|
| |
关键超参数配置结论
| 参数 | 结论 |
|---|---|
| epoch | * 16k 数据场景:3 个 epoch 为性能拐点,第 4 个 epoch 起训练 loss 虽持续下降,但验证指标不再提升,属于典型过拟合现象; * 5k 小数据场景:可将 epoch 延长至 6~8 个,充分挖掘数据价值。 |
| lr scheduler | 采用 “cosine 衰减 + 3% 比例 warmup” 的配置已足够适配任务,linear 衰减在图文对齐任务中未体现出显著优势。 |
| rank 与 alpha 设定 | * rank 值:从 8 提升至 32 时,模型对医疗影像细粒度特征的学习效果提升明显,rank 超过 64 后性能基本饱和; * alpha 值:建议按 “alpha=rank×2” 设定(如 rank=8 时对应 alpha=16),稳定性最佳。 |
| dropout | * 数据量 ≤ 10k 时:设置 dropout=0.05 可有效抑制过拟合; * 数据量 > 10k 时:无需 dropout 正则化,直接设为 0 即可。 |
安装llamafactory
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
单击上图“开始微调”按钮,进入[实例启动]页面,配置以下参数,然后单击“启动”按钮,启动实例。
- 选择镜像:系统默认镜像
lf0.9.4-tf4.57.1-torch2.8.0-cu12.6-1.1(如图①)。 - 资源配置:选择GPU,推荐卡数为4卡(如图②)。
- 选择价格模式:本实践选择“极速尊享”(如图③),不同模式的计费说明参考计费说明。
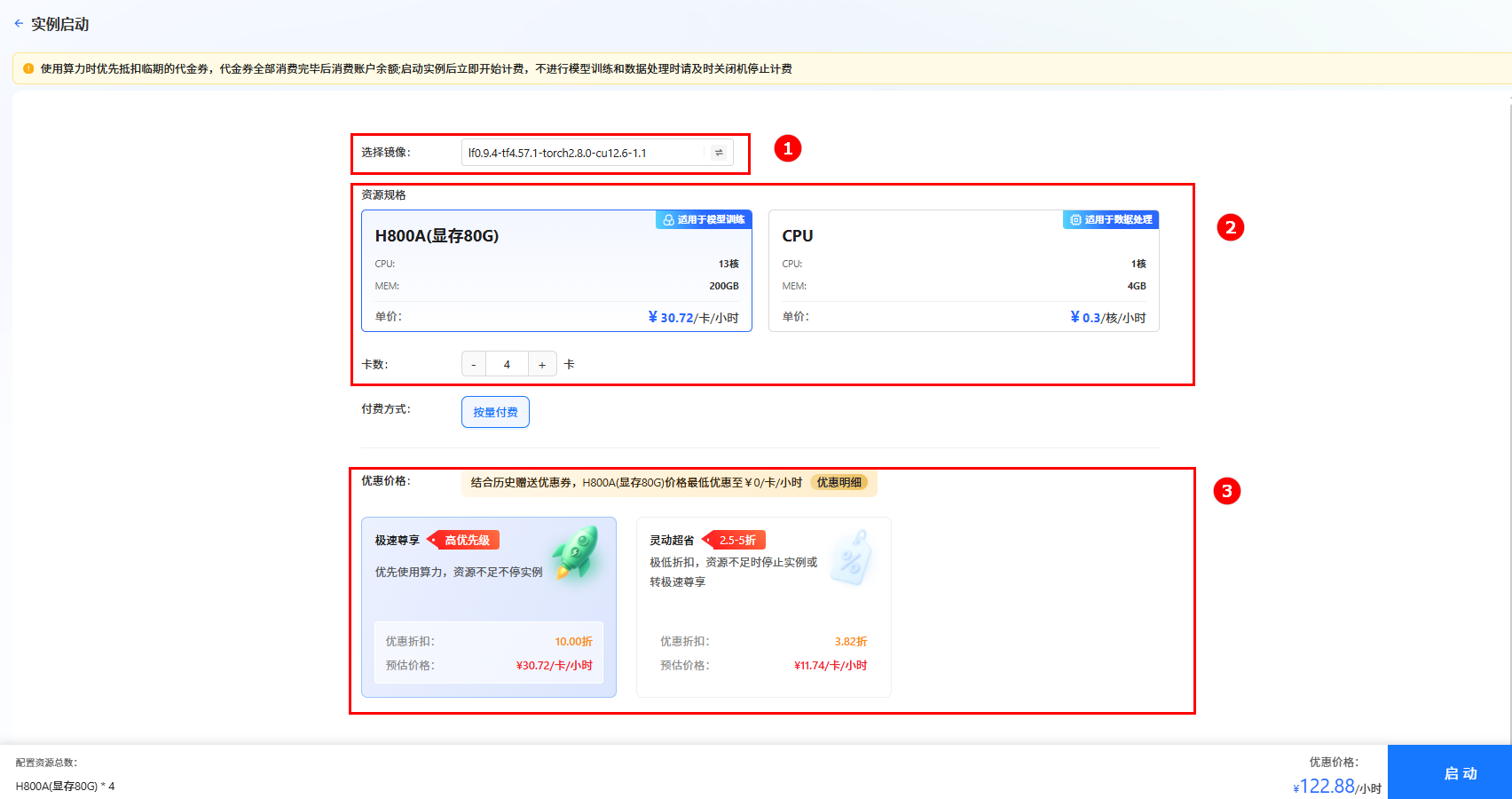 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
- 选择镜像:系统默认镜像
-
实例启动后,可启动VSCode或者JupyterLab专属数据处理,本次实践我们使用JupyterLab专属数据处理。
-
创建并配置用于数据处理的python环境。在JupyterLab中单击“Terminal”进入终端。
a. 执行如下命令,创建一个虚拟环境,python版本选择3.10。
conda create -n qwen3vl python=3.10 -yb. 执行如下命令,激活自定义的环境。
conda activate qwen3vl -
下载安装llamafactory。
a. 执行如下命令,从GitHub仓库克隆LlamaFactory项目的源代码到本地。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitb. 执行如下命令,进入项目目录。
cd LLaMA-Factoryc. 单击链接下载flash_attn,并上传至当前项目目录下,如下图所示。
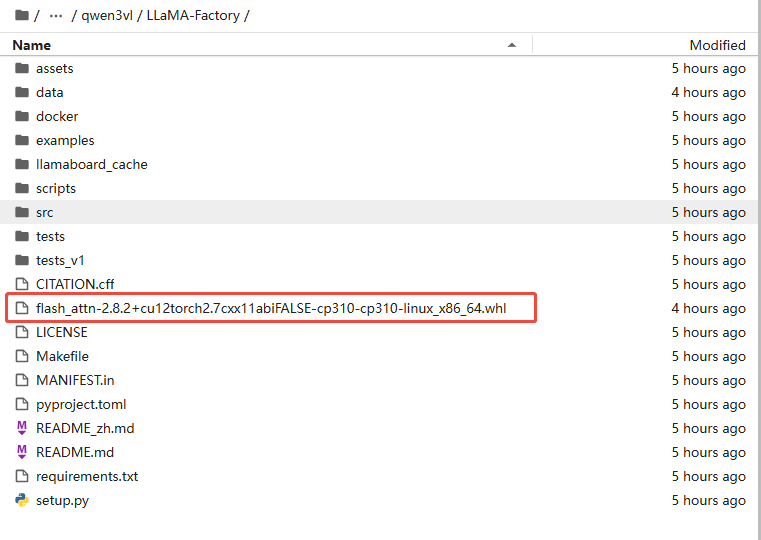
然后执行如下命令,安装flash_attn,用于加速Transformer模型(如大语言模型、多模态模型)的训练和推理。
pip install flash_attn-2.8.2+cu12torch2.7cxx11abiFALSE-cp310-cp310-linux_x86_64.whld. 执行如下命令,安装项目运行所需的所有Python依赖包。
pip install -e ".[torch,metrics]"e. 执行如下命令,安装特定版本的DeepSpeed框架,为大模型训练提供分布式加速和显存优化支持。
pip install deepspeed==0.16.9 -i https://pypi.tuna.tsinghua.edu.cn/simplef. 执行如下命令,安装ipykernel、openai,torch,为大模型开发环境配置基础依赖。
pip install ipykernel -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128 -
启动llamafactory服务,可以通过6666端口号启动。
GRADIO_SERVER_PORT=6666 llamafactory-cli webui -
访问llamafactory服务。通过复制“对外服务”网址进行llamafactory的访问。
模型训练
-
在微调页面,配置参数。其他参数保持不变,需要配置如下参数:
- 语言:选择
zh,如图①; - 模型:选择
Qwen3-vl-30B-A3B-Instruct,如图②; - 模型路径:在预置路径前加上
/shared-only/models/,如图③; - 对话模版:选择
qwen3_vl,如图④; - 数据集路径:设置为
/workspace/llamafactory/data,如图⑤; - 数据集:选择数据集
mllm_train_data,如图⑥; - 批处理大小:设置为
32,如图⑦; - “其他参数设置”中的“额外参数”:设置为模型微调日志文件的输出路径
{"output_dir": "/workspace/user-data/datasets/ouptput/lora/train"},如图⑧,后续在模型对话和模型微调时,需要在检查点路径处使用该路径; - Deepspeed Stage:设置为
3,适合训练超大模型的场景,如图⑨。提示Deepspeed Stage是DeepSpeed中ZeRO(Zero Redundancy Optimizer)优化技术的阶段参数,其范围是none、2、3。参数越大,意味着模型状态的分片程度越高,每个GPU的内存占用越少,但同时通信开销也可能越大。
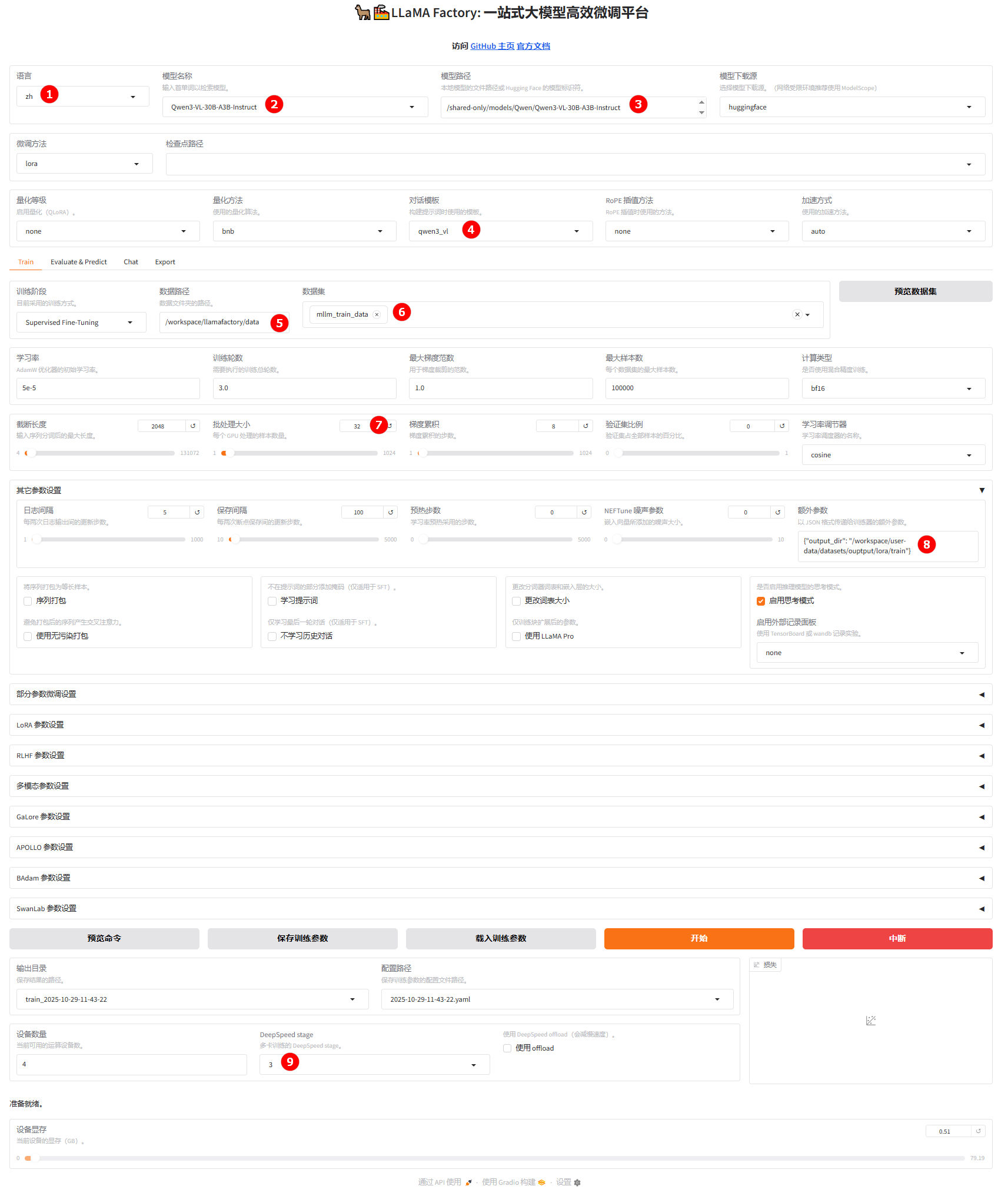
- 语言:选择
-
单击“开始”,启动微调。
提示启动微调后,您可以使用
nvidia-smi命令实时查看GPU使用情况(包括占用率、显存使用、进程等)。训练完成后,页面底部将实时显示微调过程中的日志信息,同时展示当前微调进度及Loss变化曲线。经过多轮微调后,从图中可以看出Loss逐渐趋于收敛(如图①),微调完成后,系统提示“训练完毕”(如图②)。

模型评估
- 微调后模型评估
- 原生模型评估
-
切换至“Evaluate & Predict”页面,选择训练完成的检查点路径(如图①),然后选择测试数据集
mllm_val_data(如图②),并根据实际需求配置评估参数,本实践的参数仅需设置"批处理大小"(如图③)和评估结果的“输出目录”(如图④)。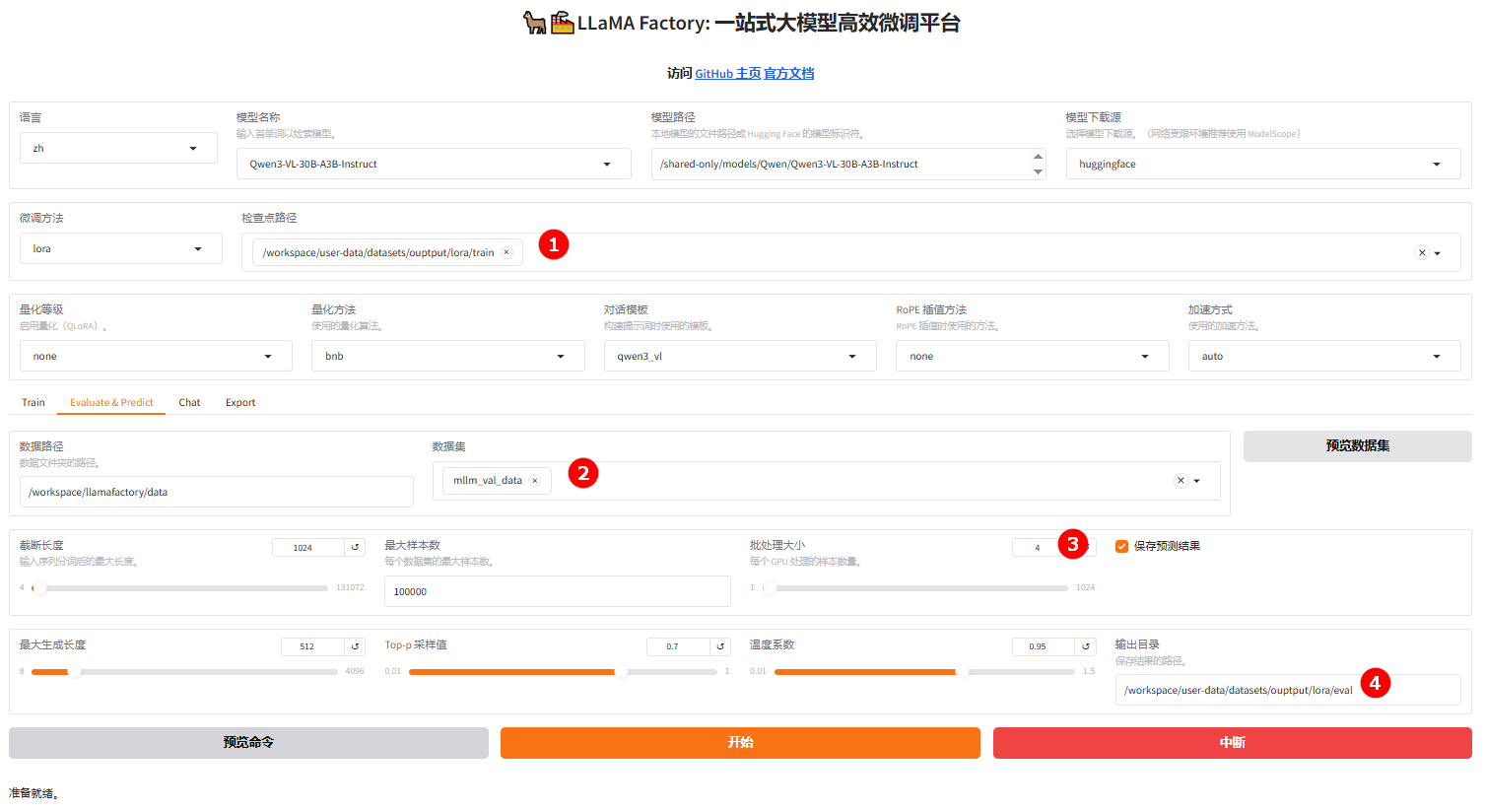
-
参数配置完成后,单击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 35.18934065594059,
"predict_model_preparation_time": 0.008,
"predict_rouge-1": 33.03964625618812,
"predict_rouge-2": 12.829063180693069,
"predict_rouge-l": 22.233395915841587,
"predict_runtime": 3580.8431,
"predict_samples_per_second": 0.903,
"predict_steps_per_second": 0.056
}结果解读:微调后模型的各项指标均显著提升:BLEU-4从0.806升至35.189,ROUGE-1从2.778升至33.039,ROUGE-2从0.006升至12.829,ROUGE-L从2.013升至22.233,表明微调有效改善了生成文本与参考文本在n-gram匹配和整体结构上的一致性,生成质量和准确性有了实质性进步。
-
切换至“Evaluate & Predict”页面,清空检查点路径(如图①),然后选择测试数据集
mllm_val_data(如图②),并根据实际需求配置评估参数,本实践的参数仅需设置"批处理大小"(如图③)和评估结果的“输出目录”(如图④)。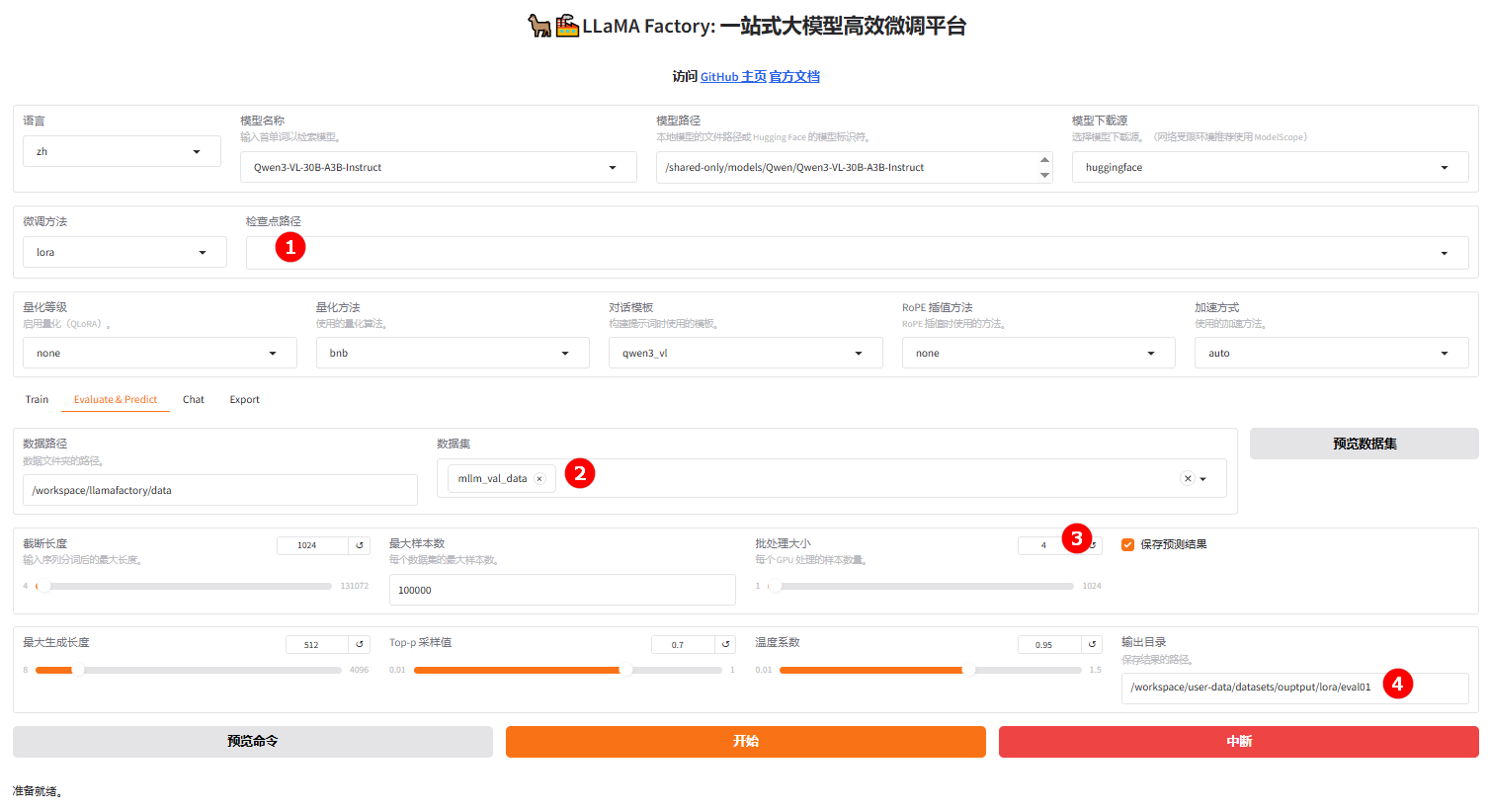
-
完成配置后,单击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 0.8059522277227722,
"predict_model_preparation_time": 0.0077,
"predict_rouge-1": 2.7779008044554456,
"predict_rouge-2": 0.005617543316831684,
"predict_rouge-l": 2.013397834158416,
"predict_runtime": 4179.8341,
"predict_samples_per_second": 0.773,
"predict_steps_per_second": 0.048
}结果解读:原生模型评估结果各项指标较低,"predict_bleu-4" 为0.806,ROUGE-1为2.778,ROUGE-2为0.006,ROUGE-L为2.013,说明生成文本在n-gram匹配和整体结构上与参考的一致性很差,生成质量与准确性明显不足。predict_runtime为 4179.8341,predict_samples_per_second为0.773,predict_steps_per_second为0.048,表明推理耗时较长,吞吐效率极低。该原生模型在生成质量和推理性能上均表现不佳,不适用于对生成质量、推理速度有要求的场景,需通过优化或微调等方式大幅提升。
对比微调后与原生模型评估结果可以看出,二者在生成质量和运行效率上均存在显著差异,微调模型全方位超越原生模型: 原生模型生成质量指标极低(BLEU-4仅0.81、ROUGE-2接近0),内容与参考答案关联弱、逻辑差,且效率偏低(单样本速度0.773),无法满足基础需求。微调模型实现质的飞跃:生成质量指标较原生提升43-2290倍,短语、词汇、句级匹配精度大幅提高;效率提升超16%,兼顾性能与速度。
综上,微调后的模型解决了原生模型核心问题,应用潜力极高,可适配图文生成、文本理解等多模态场景。
模型对话
- 微调后模型对话
- 原生模型对话
-
切换至“chat”页面,选择训练完成的检查点路径(如图①),单击“加载模型”按钮(如图②)。
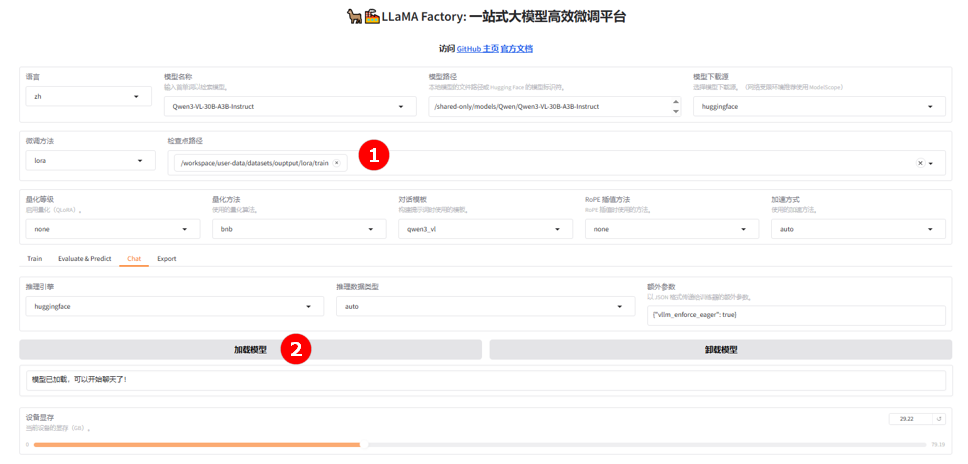
-
微调的模型加载后,其余配置保持不变,进行模型对话。用户上传图片(如图①),然后输入提问(如图②),并单击“提交”(如图③),观察模型回答(如图④)。
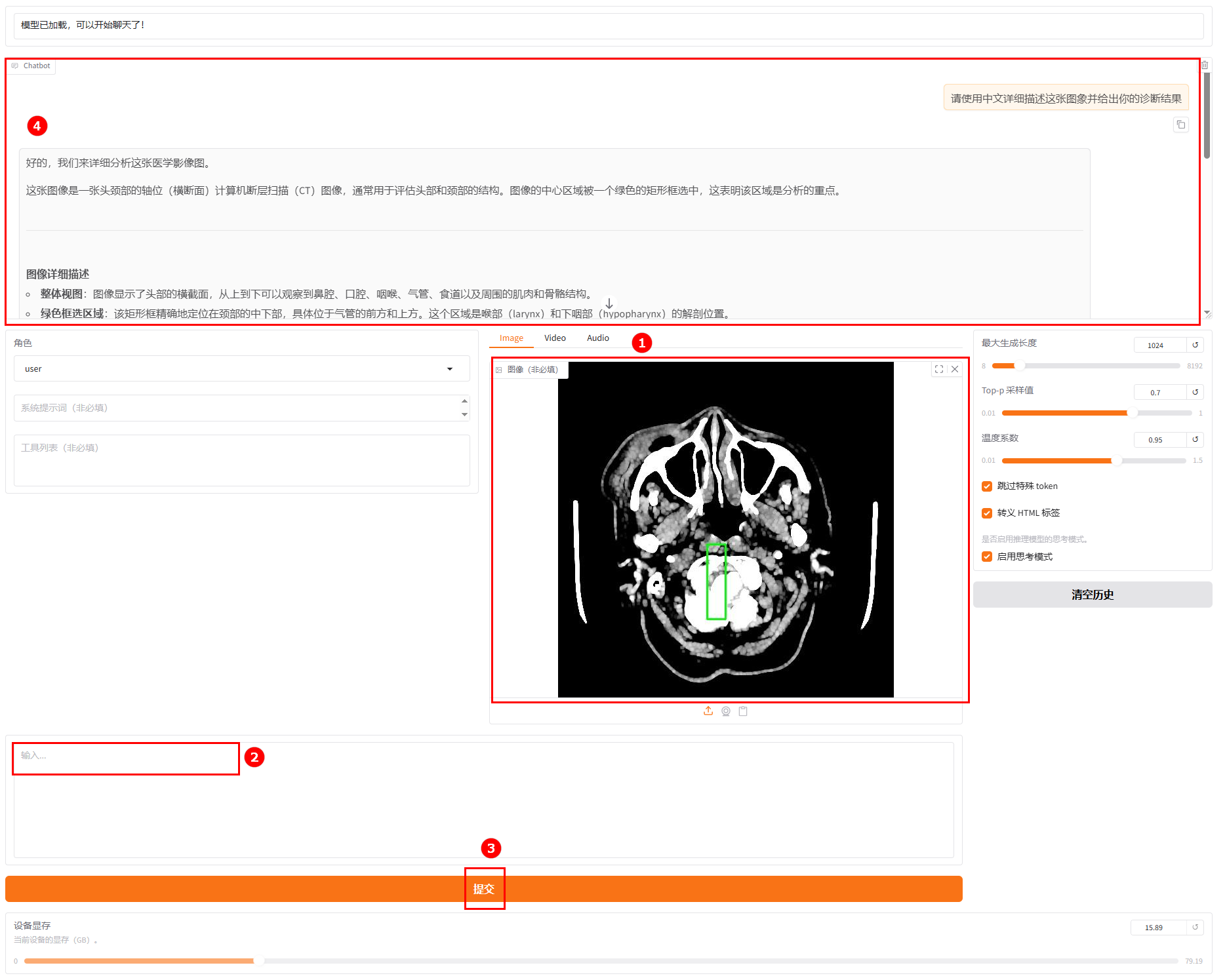
-
微调后模型对话结果的详情信息,如下图所示。
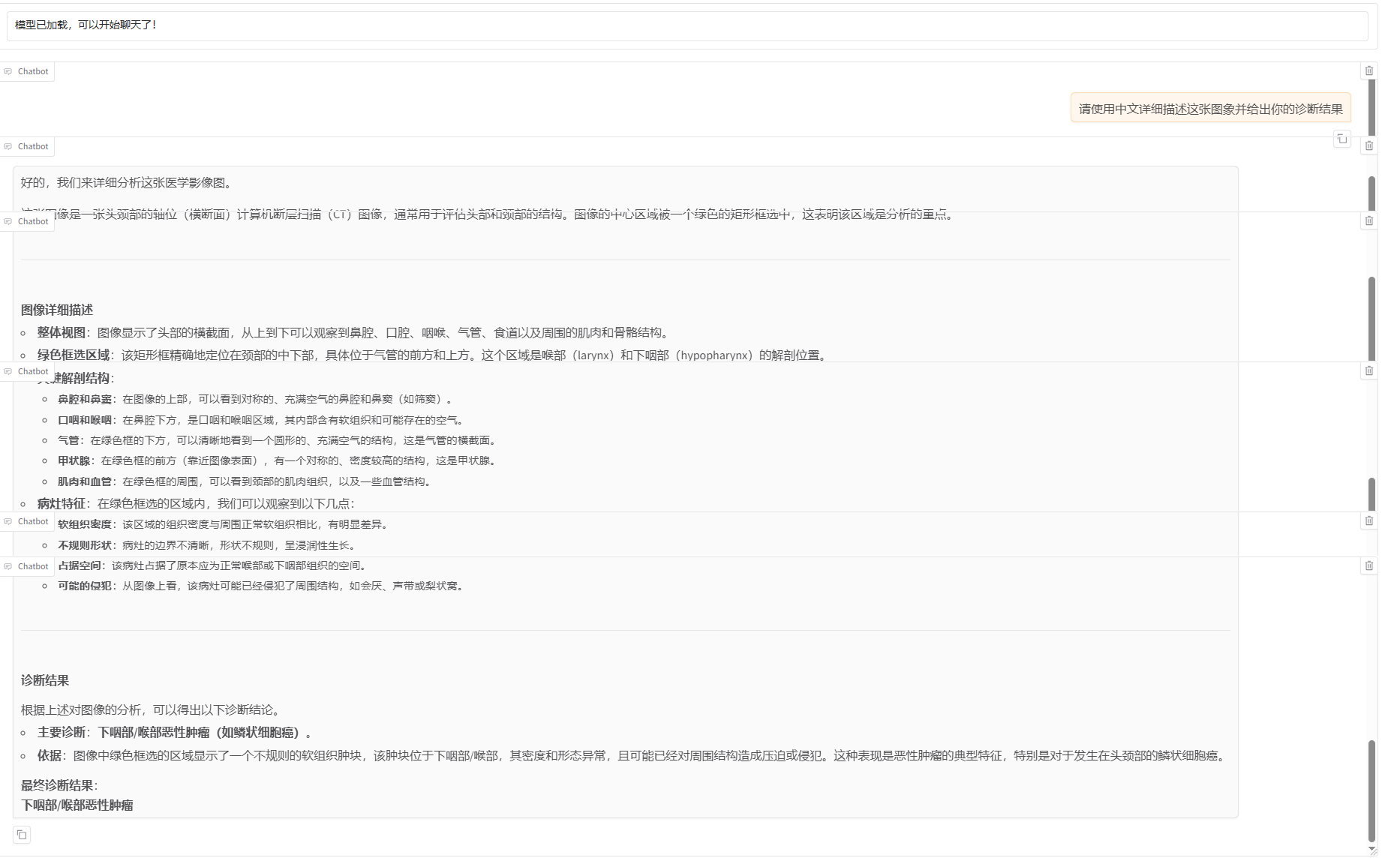
-
单击“卸载模型”按钮(如图①),卸载微调后的模型,然后清空“检查点路径”(如图②),单击“加载模型”按钮(如图③),加载原生的
Qwen3-vl-30B-A3B-Instruct模型。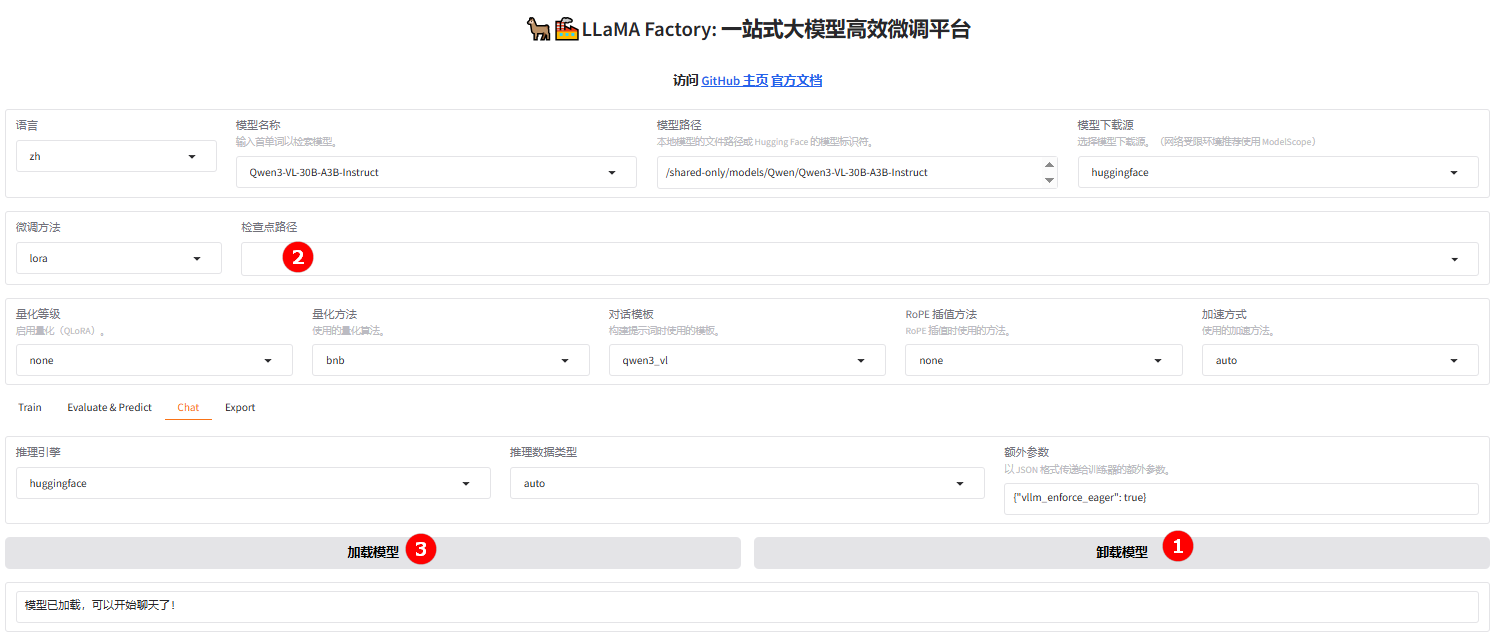
2.原生模型加载后,其余配置保持不变,进行模型对话。用户上传图片(如图①),然后输入提问(如图②),并单击“提交”(如图③),观察模型回答(如图④)。
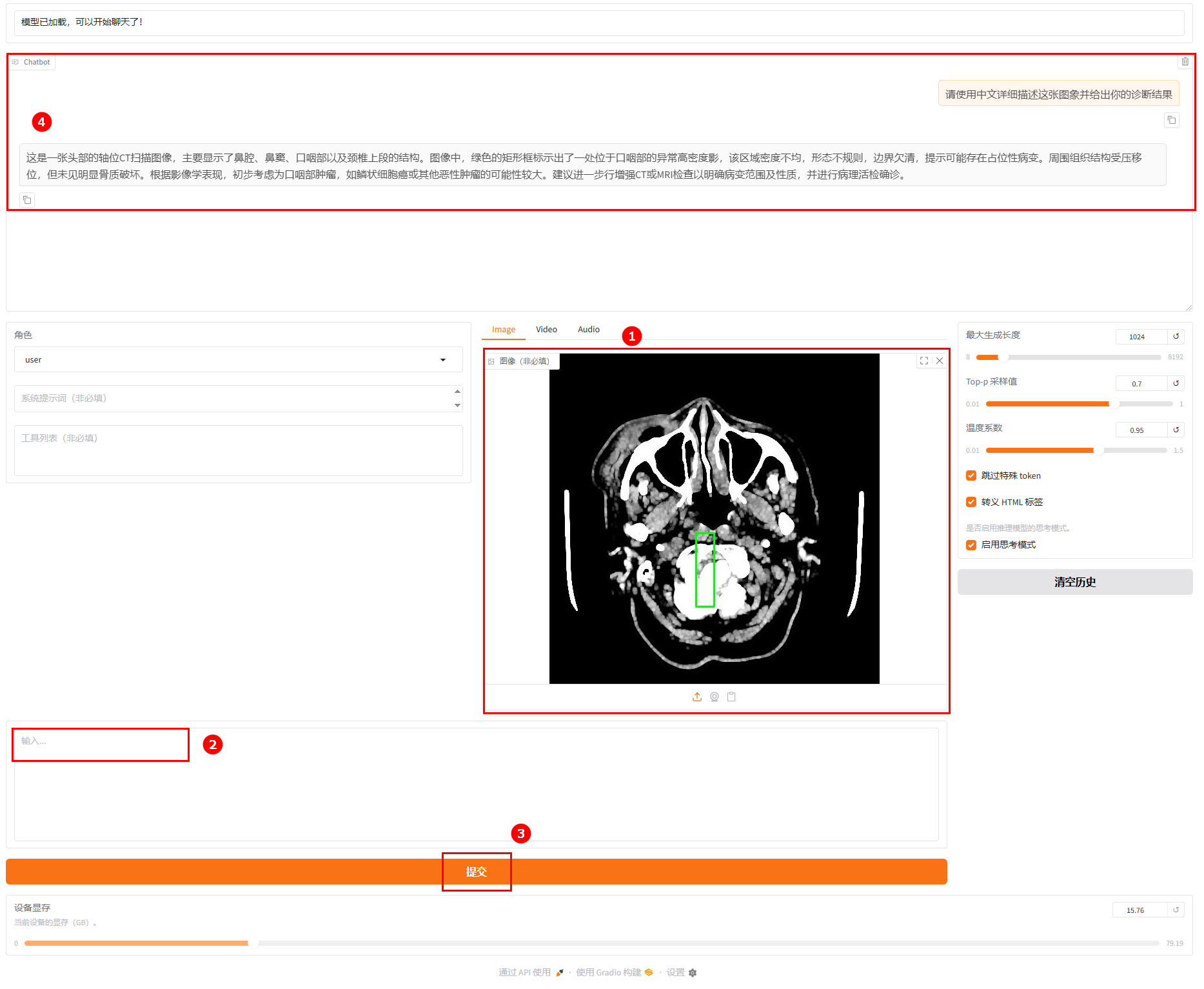
观察微调后的模型与原生模型的对话结果,发现:微调后的模型在医学影像分析的 “精细化描述、专业解剖分析、严谨诊断推理” 三个方面均显著优于原始模型,体现了针对医疗场景微调后在专业领域的能力提升。
总结
综合来看,Qwen3-vl-30B-A3B-Instruct作为性能与效率均衡的新一代多模态模型,借助LlamaFactory Online平台,通过MedTrinity-25M小数据集的LoRA微调,在医疗多模态场景中展现出显著提升 —— 微调后模型在图像描述精细度、解剖分析专业性及诊断推理严谨性上的进步,不仅验证了 “小数据 + 稀疏激活” 模式在医疗领域落地的可行性与高效性,更为大模型在专业医疗场景的精准应用提供了极具价值的实践范例,凸显了开源模型与轻量化微调方案在垂直领域快速赋能的潜力。