模型对话
平台预置了丰富的公共对话模型,支持多种类型模型的灵活交互,包括基础大模型与LoRA微调模型之间的对话。在个人任务中心,您也可以自由选用LoRA/全量模型的任意中间checkpoint作为对话模型,平台将根据所选模型自动分配相应的模型对话GPU资源。此外,平台支持多模型对话对比功能,详情可参见下文。
LoRA模型和公共模型现已开放对话限时免费活动,欢迎您体验。
前提条件
-
您已经获取LlamaFactory Online账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
-
如果您希望使用公共模型之外的模型进行对话,那么需要有微调后的模型,如果需要帮助,可参考模型微调。
概览
模型对话功能支持单个模型对话,同时也支持多模型对话,页面例如下图所示。页面说明可参看下表。
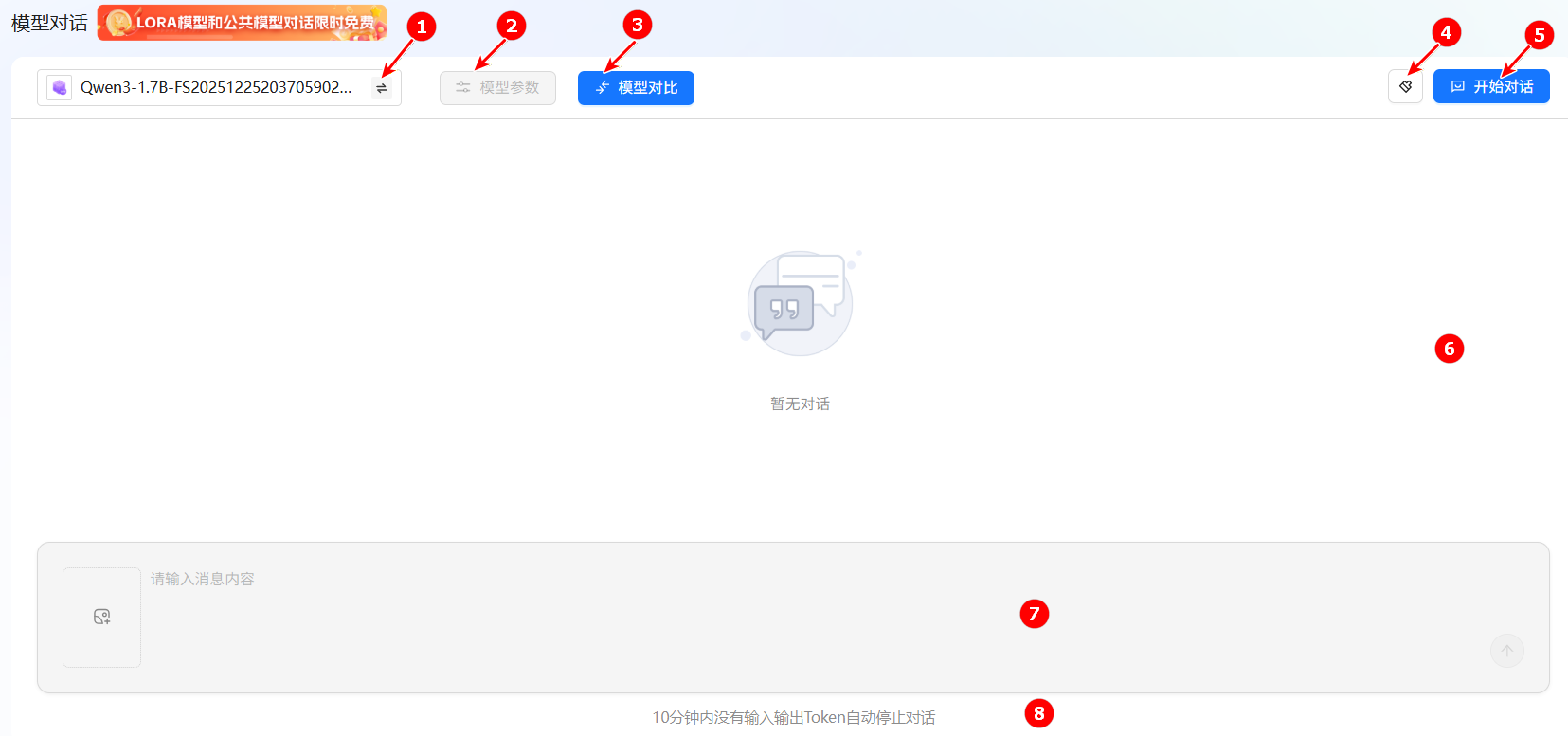
| 序号 | 参数项 | 说明 |
|---|---|---|
| 1 | 切换模型 | 用户可在此切换不同模型进行对话,每次仅可选择一个模型。 |
| 2 | 模型参数 | 用户可自定义配置当前所选模型的详细参数,具体说明请参见下文。 |
| 3 | 模型对比 | 平台支持模型对比功能,您可在模型列表中选择多个模型进行并行对话与效果比较。 |
| 4 | 对话清除 | 单击此按钮,将清空当前所有对话记录。 |
| 5 | 开始对话 | 请点击此按钮,以激活已选模型并开始对话。 |
| 6 | 对话输出区域 | 此区域用于展示模型的回复及完整的对话内容。 |
| 7 | 提示词输入区 | 您可在此输入提示词或上传图片,向模型发起对话请求。 |
| 8 | 对话提示区 | 为节省资源,若连续10分钟内无任何输入或输出(Token交互),对话将自动结束。 |
操作步骤
单个模型对话
-
登录LlamaFactory Online账号,进入控制台,点击左侧导航栏处的“微调/模型对话”,进入模型对话界面。
-
单击
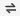 按钮选择要进行对话的模型,您可选择任务中心已有模型、已有模型LoRA或者平台已预置的模型,预置模型详情可查看附录,配置页面例如下图所示。
按钮选择要进行对话的模型,您可选择任务中心已有模型、已有模型LoRA或者平台已预置的模型,预置模型详情可查看附录,配置页面例如下图所示。
-
模型/中间checkpoint选择完成后,单击“确定”按钮,即可完成选择模型操作。
-
模型选择完成后,单击“开始对话”按钮,进入模型对话资源概览页面,例如下图所示,系统会根据选择模型自动匹配所需的GPU资源。
 提示
提示平台支持多模态对话理解,模型的详细信息,可参见附录中对话类型的相关注解。
-
单击“立即对话”按钮,进入对话创建页面,例如下图所示。
-
模型激活成功后,对话状态将更新为“对话中”。此时,您可在下方输入框中输入提示词,开始与模型进行交互。页面示例如下所示,可调整的模型参数详情请参见下表。
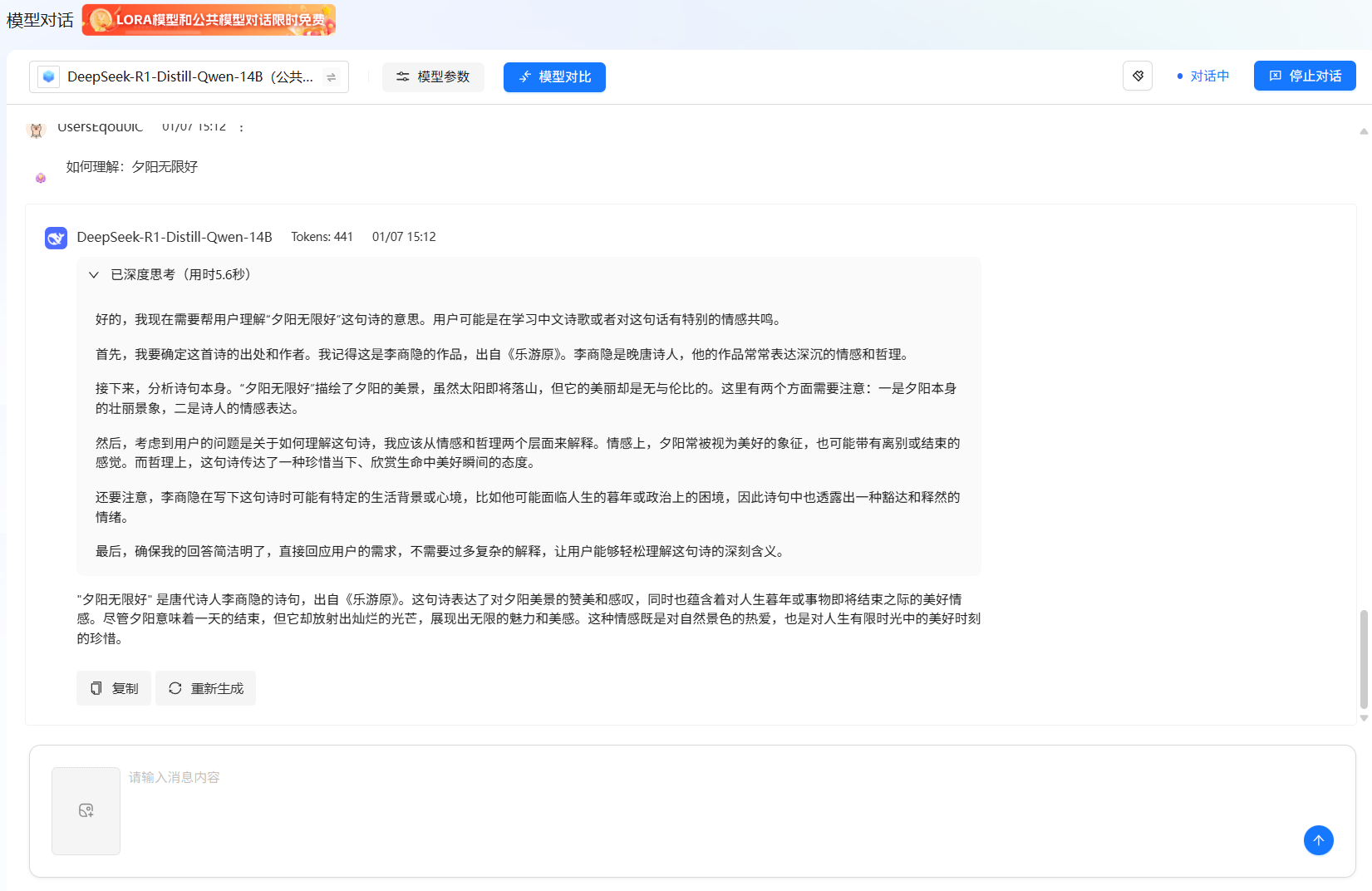
参数名称 当前值 最小值 最大值 说明 System Prompt (用户输入) - - 系统提示词,定义AI的角色定位和对话规则,比如"你是一个优秀的助手"。优质的提示词能显著提升回答质量。。 Temperature 0.7 0 2 采样温度,控制AI输出的确定性:低值(如0.2)更保守、确定,适合事实问答、代码生成;高值(如0.8-1.2)更创意、多样,适合创意写作、头脑风暴。 Top_p 1.0 0.1 1 核采样,与温度参数协同工作,通常只需调整一个。设为0.9时,模型仅从累积概率前90%的词汇中采样,既保证多样性又过滤掉荒谬选项 Top_k 50 0 100 最高K采样,每次预测时,仅考虑概率最高的前K个词。设为50是一个常用值,在保证质量的同时允许一定随机性。 Max Tokens 6144 - 12288 最大总令牌数, 指 "输入+输出" 的总长度上限。超过此限制,生成会提前结束或报错。 Max New Tokens 5120 0 10240 最大新令牌数, 指仅生成部分的长度上限。这是更常用的控制参数,确保生成的回复不会过长。请务必确保Max New Tokens小于等于Max Tokens令牌数。 Repetition Penalty 1.1 0 2 重复惩罚因子,控制重复内容的出现概率,值越高(如1.2)越避免重复,值越低(如0.8)越容易重复。通常设为1.0-1.2,过高会导致输出不连贯。 Deep Thinking False - - 深度思考模式开关,部分模型支持该参数,支持的模型默认开启该参数。 -
您可点击对话框右上角
 清除对话历史,开始新一轮对话,但当对话停止后,不能清除对话历史。
清除对话历史,开始新一轮对话,但当对话停止后,不能清除对话历史。 -
点击右上角 “停止对话”,取消部署,对话状态变为停止。
信息bloomz-3B和GPT2-small模型在进行vllm推理对话的时候,在webUI界面需要添加对应的模型最大长度参数才能正确加载模型进行对话。
bloomz-3B模型支持的最大长度是2048,GPT2-small支持的最大长度是1024,下面以GPT为例进行说明, 有两种添加方式:
第一种:
{"vllm_enforce_eager": true, "vllm_maxlen":1024}第二种:
{"vllm_enforce_eager": true, "vllm_config":{"max_model_len": 1024}}详情参考 参数介绍。
-
模型对比对话
-
登录LlamaFactory Online账号,进入控制台,点击左侧导航栏处的“微调/模型对话”,进入模型对话页面。
-
选择单个模型对话,选择进行对话的模型,操作步骤可参看单个模型对话章节对应章节所述。
您可选择单个对话完成后再开启开启新对话,也可以在一个模型激活后选择新模型。
-
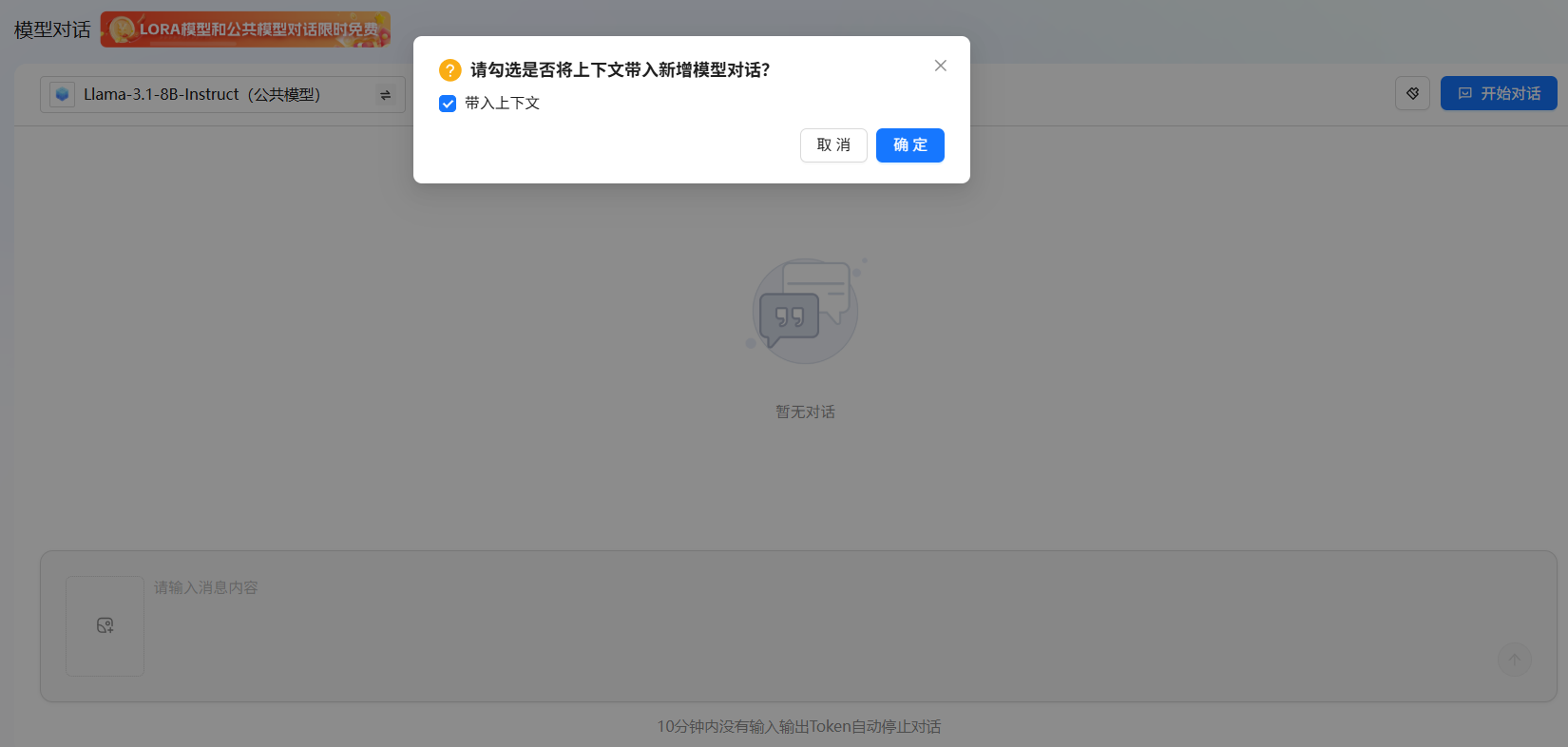
单击“模型对比”按钮,进入[选择模型]页面,模型说明可参看附录,模型选择完成后,进入上下文勾选页面,例如下图所示,下文以带入上下文为例进行说明。
-
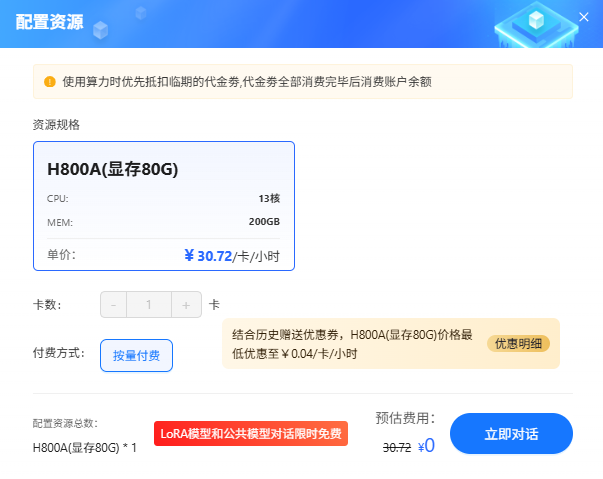
单击“确定”按钮进入模型对话资源概览页面,例如下图所示,系统会根据选择模型自动匹配所需的GPU资源,例如下图所示。
-
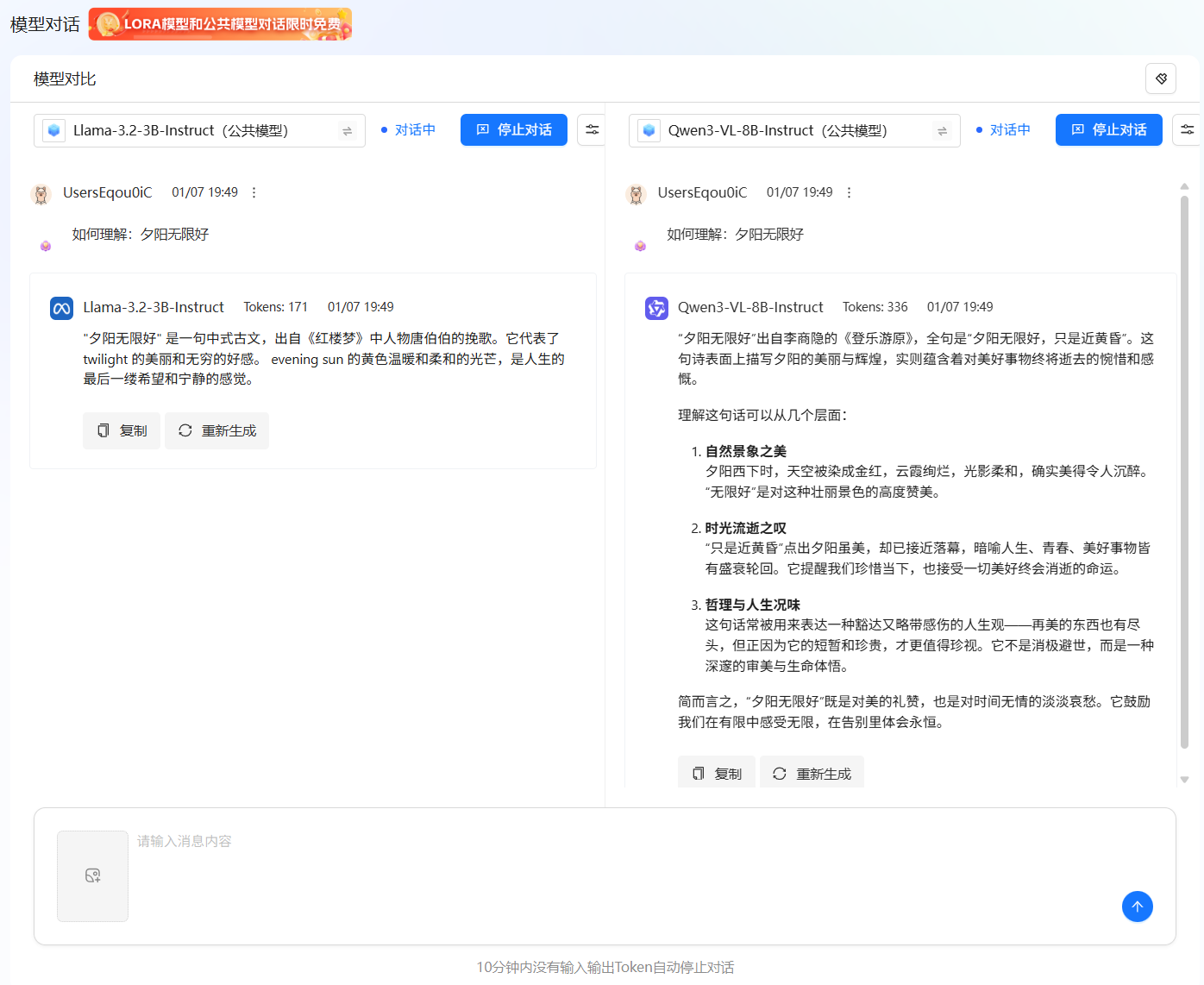
资源选择完成后,单击“开始对话”按钮,模型激活完成后,对话状态将切换为“对话中”。此时,您可以在下方的输入框中输入提示词,开始与模型对话。页面示例如下图所示,可调整的模型参数详情请参见上表。
 提示
提示为避免资源浪费,若10分钟内无任何输入或输出,系统将自动终止对话。
附录
| model_name | GPU资源 | 参数量 | 最大LoRA数量 | 对话类型 | 对话模板 |
|---|---|---|---|---|---|
| Llama-3.2-3B | 1 | 3 | 20 | 文本对话 | llama3 |
| Qwen3-32B | 2 | 32 | 20 | 文本对话 | qwen3 |
| Qwen3-14B | 1 | 14 | 20 | 文本对话 | qwen3 |
| Qwen3-8B | 1 | 8 | 20 | 文本对话 | qwen3 |
| Qwen3-4B | 1 | 4 | 20 | 文本对话 | qwen3 |
| Qwen3-1.7B | 1 | 1.7 | 20 | 文本对话 | qwen3 |
| DeepSeek-R1-Distill-Qwen-14B | 1 | 14 | 20 | 文本对话 | deepseek |
| DeepSeek-R1-Distill-Llama-8B | 1 | 8 | 20 | 文本对话 | deepseek |
| Qwen2.5-14B-Instruct | 1 | 14 | 20 | 文本对话 | qwen |
| Qwen2.5-32B-Instruct | 2 | 32 | 20 | 文本对话 | qwen |
| Qwen2.5-7B-Instruct | 1 | 7 | 20 | 文本对话 | qwen |
| DeepSeek-R1-Distill-Qwen-7B | 1 | 7 | 20 | 文本对话 | deepseek |
| Qwen2.5-1.5B-Instruct | 1 | 1.5 | 20 | 文本对话 | qwen |
| Qwen2-VL-2B-Instruct | 1 | 2 | 20 | 支持多模态 | qwen |
| Qwen2.5-VL-3B-Instruct | 1 | 3 | 20 | 支持多模态 | qwen2_vl |
| Qwen2.5-VL-7B-Instruct | 1 | 7 | 20 | 支持多模态 | qwen2_vl |
| Qwen2.5-VL-32B-Instruct | 2 | 32 | 20 | 支持多模态 | qwen2_vl |
| Qwen2.5-VL-72B-Instruct | 4 | 72 | 20 | 支持多模态 | qwen2_vl |
| DeepSeek-R1-Distill-Llama-70B | 4 | 70 | 20 | 文本对话 | deepseek |
| Qwen2.5-72B-Instruct | 4 | 72 | 20 | 文本对话 | qwen |
| Llama-3.1-8B-Instruct | 1 | 8 | 30 | 文本对话 | llama3 |
| Meta-Llama-3-8B-Instruct | 1 | 8 | 30 | 文本对话 | llama3 |
| Meta-Llama-3-70B-Instruct | 4 | 70 | 20 | 文本对话 | llama3 |
| Meta-Llama-3-8B | 1 | 8 | 30 | 文本对话 | llama3 |
| Llama-2-7b | 1 | 7 | 30 | 文本对话 | llama2 |
| DeepSeek-R1-0528-Qwen3-8B | 1 | 8 | 30 | 文本对话 | deepseek |
| Qwen3-4B-Thinking-2507 | 1 | 4 | 20 | 文本对话 | qwen3 |
| Qwen3-4B-Instruct-2507 | 1 | 4 | 20 | 文本对话 | qwen3 |
| MiniCPM4-8B | 1 | 8 | 20 | 文本对话 | cpm |
| MiniCPM-V-4_5 | 1 | 8 | 20 | 文本对话 | cpm |
| Qwen3-VL-4B-Thinking | 1 | 4 | 20 | 支持多模态 | qwen3_vl |
| Qwen3-VL-8B-Thinking | 1 | 8 | 20 | 支持多模态 | qwen3_vl |
| Qwen3-VL-8B-Instruct | 1 | 8 | 20 | 支持多模态 | qwen3_vl |
| Qwen3-VL-30B-A3B-Instruct | 4 | 30 | 20 | 支持多模态 | qwen3_vl |
| Qwen3-VL-30B-A3B-Thinking | 4 | 30 | 20 | 支持多模态 | qwen3_vl |
| Qwen3-VL-4B-Instruct | 1 | 4 | 20 | 支持多模态 | qwen3_vl |
| MobiMind-Grounder-3B | 1 | 3 | 20 | 支持多模态 | qwen2_vl |
| Qwen3-Coder-30B-A3B-Instruct | 1 | 30 | 5 | 文本对话 | qwen3 |
| Llama-3.2-3B-Instruct | 1 | 3 | 20 | 文本对话 | llama3 |